
Lecture 8: Further on NLP#
In this lecture, we will learn how to do basic sentiment analysis and topic modelling. From both we will further understand of the critical role of the pre-processing step and the word and document vectorization we learned i Lecture 8.
Intro to Sentiment Analysis#
What is sentiment analysis and how to do it?#
Sentiment analysis in essence is introduced to solve a text classification problem according to the text’s potential emotional value. In short, sentiment analysis aims to classify a given text into an overall positive and negative emotional categories. There are in general two approaches to do it depending on wether we have suitable labeled data to apply sentiment analysis on a given text:
Lexicon base sentiment analyser.
Machine learning model of sentiment classifier.
We will discuss examples of each approach in details below.
The Sentiment Lexicon approach#
A lexicon is a collection of words compiled using expert knowledge for a specific purpose. Sentiment lexicons contain commonly used words and the sentiment associated with them, such as: ‘happy’ (with a sentiment score of 1) or ‘frustrated’ (with a sentiment score of -1). The assigned negative and positive values indicates sentiment polarity; the assigned magnitude indicates the strength.
There are several standard English sentiment lexicons with varying vocabulary size and representation that we can use, including:
AFINN Lexicon (3300 words, each with a sentiment score range of -3 to +3).
Bing Liu’s lexicon (6800 words in separate positive and negative lists;
Using any of these Sentiment Lexicons, a sentiment analyses score of a given text (document, sentences, phrases, or words) is computed based on the sentiment score of each word in the text which is found in the chosen lexicon.
VADER Examples of sentiment analysis with NLTK#
Below, we present two examples to perform sentiment analysis with two of the Sentiment Lexicons available in NLTK module. For these examples, we will use the following text data and VADER lexicon from NLTK which may need to be downloaded first usign nltk.download() if you have never done it:
twitter_samples: Sample of Twitter posts
movie_reviews: Two thousand movie reviews categorized by Bo Pang and Lillian Lee
vader_lexicon: A scored list of words and jargon created by C.J. Hutto and Eric Gilbert
The vader_lexicon is NLTK pre-trained sentiment analyser of VADER (Valence Aware Dictionary and sEntiment Reasoner). This lexicon is best suited for language used in social media (short sentences). It is considered to be less accurate for longer, structured sentences.
To use NLTK’s VADER Lexicon, we:
First, create an instance of
nltk.sentiment.SentimentIntensityAnalyzer, thenUse the .polarity_scores() method on the text (a string object) which we want to sentiment-analyse.
In Python, these steps are performend as shown in the following example codes. The output of this short example is reproduced below.
VADER sentiment analysis:
{'neg': 0.0, 'neu': 0.295, 'pos': 0.705, 'compound': 0.8012}
The interpretation NLTK SentimentIntensityAnalyzer.polarity_scores() can be interpreted as follows:
There are 4 different scores reported by VADER:
The three scores labeled with ‘neg’, ‘neu’, and ‘pos’ sum to 1. So, these may be interpreted as probabilities. For example, there is a 0.705 probability that the sentiment value of the text (i.e
sentence1) is positive.The score labeled ‘compound’ is the aggregate sentiment score. This can be thought of as the overall normalised sum of (‘neg’, ‘neu’ and ‘pos’). This sum also ranges from -1 to 1.
# VADER example 1
from nltk.sentiment import SentimentIntensityAnalyzer
vader = SentimentIntensityAnalyzer()
sentence1 = "Wow, NLTK is really powerful!"
print("VADER sentiment analysis:\n", vader.polarity_scores(sentence1))
---------------------------------------------------------------------------
LookupError Traceback (most recent call last)
Cell In[1], line 3
1 # VADER example 1
2 from nltk.sentiment import SentimentIntensityAnalyzer
----> 3 vader = SentimentIntensityAnalyzer()
4 sentence1 = "Wow, NLTK is really powerful!"
5 print("VADER sentiment analysis:\n", vader.polarity_scores(sentence1))
File ~/.cache/pypoetry/virtualenvs/inf80054-notes-uAdlCNO7-py3.12/lib/python3.12/site-packages/nltk/sentiment/vader.py:340, in SentimentIntensityAnalyzer.__init__(self, lexicon_file)
336 def __init__(
337 self,
338 lexicon_file="sentiment/vader_lexicon.zip/vader_lexicon/vader_lexicon.txt",
339 ):
--> 340 self.lexicon_file = nltk.data.load(lexicon_file)
341 self.lexicon = self.make_lex_dict()
342 self.constants = VaderConstants()
File ~/.cache/pypoetry/virtualenvs/inf80054-notes-uAdlCNO7-py3.12/lib/python3.12/site-packages/nltk/data.py:953, in load(resource_url, format, cache, verbose, logic_parser, fstruct_reader, encoding)
950 print(f"<<Loading {resource_url}>>")
952 # Load the resource.
--> 953 opened_resource = _open(resource_url)
955 if format == "raw":
956 resource_val = opened_resource.read()
File ~/.cache/pypoetry/virtualenvs/inf80054-notes-uAdlCNO7-py3.12/lib/python3.12/site-packages/nltk/data.py:1079, in _open(resource_url)
1076 protocol, path_ = split_resource_url(resource_url)
1078 if protocol is None or protocol.lower() == "nltk":
-> 1079 return find(path_, path + [""]).open()
1080 elif protocol.lower() == "file":
1081 # urllib might not use mode='rb', so handle this one ourselves:
1082 return find(path_, [""]).open()
File ~/.cache/pypoetry/virtualenvs/inf80054-notes-uAdlCNO7-py3.12/lib/python3.12/site-packages/nltk/data.py:696, in find(resource_name, paths)
694 sep = "*" * 70
695 resource_not_found = f"\n{sep}\n{msg}\n{sep}\n"
--> 696 raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource 'vader_lexicon' not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('vader_lexicon')
For more information see: https://www.nltk.org/data.html
Attempted to load 'sentiment/vader_lexicon.zip/vader_lexicon/vader_lexicon.txt'
Searched in:
- '/home/codespace/nltk_data'
- '/home/codespace/.cache/pypoetry/virtualenvs/inf80054-notes-uAdlCNO7-py3.12/nltk_data'
- '/home/codespace/.cache/pypoetry/virtualenvs/inf80054-notes-uAdlCNO7-py3.12/share/nltk_data'
- '/home/codespace/.cache/pypoetry/virtualenvs/inf80054-notes-uAdlCNO7-py3.12/lib/nltk_data'
- '/usr/share/nltk_data'
- '/usr/local/share/nltk_data'
- '/usr/lib/nltk_data'
- '/usr/local/lib/nltk_data'
- ''
**********************************************************************
Setiment analysis of NLTK twitter posts#
In the next example, we will use VADER lexicon to do sentiment analysis of a sample of Twitter posts in NLTK. After downloading the sample and import it into Python, we load the data onto a DataFrame object twitter_df.
#download NLTK twitter samples
nltk.download(['twitter_samples'])
#importing twitter_samples
from nltk.corpus import twitter_samples
# load tweets into DataFrame
twitter_df = pd.DataFrame()
twitter_df['tweet'] = twitter_samples.strings()
Originally, NLTK’s Twitter post sample contains 30,000 posts. For our example, we select a random sample of 1000 which we obain by issuing the following codes:
# there are 30000 tweets in the sample; let's just 1000 random sample
twitter_df = twitter_df.sample(n=1000, random_state=5)
Note
Setting random_state to a specific value ensures for reproducibility of our analysis. If we do not set random_state, then the next time we run the Python codes we may always get a slightly different result due to the sample is randomised.
We will store the sentiment analysis score of each Twitter post in a new column of the DataFrame twitter_df. We will name this new column as sentiment.
twitter_df['sentiment'] = twitter_df['tweet'].apply(
lambda tweet: sentimentclass(tweet,threshold))
twitter_df.head()
In the above code, we apply a lambda function which will call our own custom function (sentimentclass()) which will score the sentiment value of each row in twitter_df['tweet'] column.
Our custom function wwhich we call as sentimentclass(sentence, threshold=0): is where the actual VADER sentiment analysis happening. For the threshold value, we use 0.25 to reduce the number of ambiguous cases incorrectly classified. (In the next example, we will use labeled data with true human sentiment classification and then estimate a Machine Learning Classifier to do sentiment analysis. If we have such labelled data now, we can try to find the optimal threshold value which produces the highest predictive accuracy)
threshold = 0.25
# we use lambda function to apply the sentimentclass function to each row
# within 'tweet' column in twitter_df and then saving the result to a new
# column 'sentiment'
twitter_df['sentiment'] = twitter_df['tweet'].apply(
lambda tweet: sentimentclass(tweet,threshold))
twitter_df.head()
#%% Sentiment analysis of Twitter post
import nltk
import pandas as pd
# a function to classify the tweets into positive, negative or neutral
# using VADER's sentiment analysis
def sentimentclass(sentence, threshold=0):
"""
Using NLTK's VADER sentiment analysis to classifiy the input sentence
into positve, negative, or neutral.
input:
sentence a raw string containing the text to analyse the sentiment
threshold: a value between [0 and 1] to determine threshold value
for classifying the sentiment analysis score.
'pos': if score>threshold
'neg': if score<-threshold
'neu': if -threshold<score<threshold
return: 'pos', 'neu' or 'neg'
"""
from nltk.sentiment import SentimentIntensityAnalyzer
sia = SentimentIntensityAnalyzer()
vaderscore = sia.polarity_scores(sentence)['compound']
if threshold<0 or threshold>1:
threshold = 0 #default
if vaderscore > threshold:
return 'positive'
elif vaderscore <-threshold:
return 'negative'
else:
return 'neutral'
#download NLTK twitter samples
nltk.download(['twitter_samples'])
#importing twitter_samples
from nltk.corpus import twitter_samples
# load tweets into DataFrame
twitter_df = pd.DataFrame()
twitter_df['tweet'] = twitter_samples.strings()
# there are 30000 tweets in the sample; let's just 1000 random sample
twitter_df = twitter_df.sample(n=1000, random_state=5)
#create a new column in twitter_df containing the sentiment value
#we will use 0.25 as threshold to reduce ambiguous cases incorrectly
#classified (Ideally, we want labeled data with true human sentiment
#classification and then estimate a classification model to optimize
#the threshold value for the highest predictive accuracy)
threshold = 0.25
# we use lambda function to apply the sentimentclass function to each row
# within 'tweet' column in twitter_df and then saving the result to a new
# column 'sentiment'
twitter_df['sentiment'] = twitter_df['tweet'].apply(
lambda tweet: sentimentclass(tweet,threshold))
twitter_df.head()
[nltk_data] Downloading package twitter_samples to
[nltk_data] C:\Users\apalangkaraya\AppData\Roaming\nltk_data...
[nltk_data] Package twitter_samples is already up-to-date!
| tweet | sentiment | |
|---|---|---|
| 8033 | @ffsjason I'm not. datz you. :-) | neutral |
| 29952 | RT @cristinaprkr: The level of blatant misinfo... | negative |
| 2736 | Cant stand seeing my titos and titas cry :((((... | negative |
| 29677 | RT @blairmcdougall: Salmond on Sky encouraging... | positive |
| 3285 | @MsCarlyDowd we're not sure :( might have to w... | positive |
Sentiment analysis of movie reviews#
In this example, we will use NLTK’s movie_reviews database, which is a collection of movie reviews where the reviews are already classified by human. In other words, the movie review data are labelled data that can be used to develop and judge the accuracy of a machine learning classifier. In the data, the fileids’ first three letters indicate human-label of the review. For example the fileids ‘neg/cv000_29416.txt’ means the movie review text has been labelled as a negative review. To quickly identify fileids which are associated with positive and negative reviews separately, we can use movie_reviews.fileids(categories=).
positive_review_ids = movie_reviews.fileids(categories=["pos"])
negative_review_ids = movie_reviews.fileids(categories=["neg"])
To score the sentiment value, we will use the VADER lexicon sentiment analyser. Recall that VADER is likely better for sentiment analysis of short sentences such as tweet. However, the movie review text is longer than Twitter post. This means, it may be better to split each review text into separate sentences. We can then rate the sentiment score of each sentence individually followed by taking an average of the sentences’ sentiment scores.
The custom function meansentiment(review_id, threshold=0) will use NLTK’s sentence_tokenize function to split a given movie review text specified by review_id into its sentences and, for each of the sentences, compute the VADER compound sentiment scores. The function will then compute a simple average (using the mean function imported from the statistics package) of these scores and sotre it in a varaible meanscore.
sia = SentimentIntensityAnalyzer()
text = nltk.corpus.movie_reviews.raw(review_id)
scores = [sia.polarity_scores(sentence)["compound"]
for sentence in nltk.sent_tokenize(text) ]
meanscore = mean(scores)
Then, as in the previous example, the meanscore is classfied into ‘positive’, ‘negative’, or ‘neutral’ using the input threshold value.
In this example, since we have labelled sentiment data, we will try a number of threshold values [0,0.025, 0.05, 0.1,0.125, 0.15, 0.2] to find the optimal threshold value which maximize the proportion of correctly VADER classified sentiment category when compared to human classfication of the movie review’s sentiment.
#let's compare VADER to human labels of the movie reviews
for threshold in [0,0.025, 0.05, 0.1,0.125, 0.15, 0.2]:
correct = 0
neutral = 0
for review_id in all_review_ids:
if meansentiment(review_id, threshold)=='positive':
if review_id in positive_review_ids:
correct += 1
elif meansentiment(review_id, threshold)=='negative':
if review_id in negative_review_ids:
correct += 1
else:
#if neutral, then it is too ambiguous to classify by VADER
#so we will drop the case from the evaluation
neutral +=1
print(F"At threshold = {threshold}; {correct / (len(all_review_ids)-neutral):.2%} correct")
print(F"At threshold = {threshold}; {neutral} reviews were too ambiguous.")
There are 2000 moview reviews in the original NLTK’s data. To speed up the run time of this example, we will use only 100 random sample of the review.
# random sample of 100 ids
import random
random.seed(5)
sample_size = 100
sample_review_ids = random.sample([x for x in all_review_ids], sample_size)
The results seem to suggest that if we keep increasing the threshold value, the correctly classified proportion increases but at an accelerating cost of having ambiguous sentiment values. For example, at threshold = 0.2, we have 86.67% correct classfication, but 85% of the reviews cannot be classified. If any guess is better than no guess, then we may want to lower the threshold value. In this case, we may want to set the threshold at 0.025 with accuracy of 63% with only 10% of the sample unclassfied.
Question: How else can we improve from the 63% accuracy rate? There are several things to see if we can improve this accuracy while avoiding having too many unscored text.
Preprocess the review text before submitting to VADER (SentimentIntensityAnalyzer)
Drop non-English words
Identify entity names (e.g. actor’s names) and drop them
Extract/generate new features based on the review text and use them to train a better classifier
Use a better Sentiment Analyzer which is more appropriate for the type of the text.
#%% Sentiment analysis of NLTK's movie eviews
import nltk
#download NLTK twitter samples
nltk.download(['movie_reviews'])
#importing twitter_samples
from nltk.corpus import movie_reviews
#movie_reviews contains separate fileids for separate review
print(movie_reviews.fileids())
#look at an example review
#print(movie_reviews.raw('neg/cv000_29416.txt'))
#notice fileids' first three letters indicate human-label of the review
#we can use the categories of fileids to systematically identify positive
#and negative review
positive_review_ids = movie_reviews.fileids(categories=["pos"])
negative_review_ids = movie_reviews.fileids(categories=["neg"])
all_review_ids = positive_review_ids + negative_review_ids
# random sample of 100 ids
import random
random.seed(5)
sample_size = 100
sample_review_ids = random.sample([x for x in all_review_ids], sample_size)
def meansentiment(review_id, threshold=0):
"""
Return positive, negative or neural classification for the
review of the provided review_id and given threshold level
"""
from statistics import mean
from nltk.sentiment import SentimentIntensityAnalyzer
sia = SentimentIntensityAnalyzer()
text = nltk.corpus.movie_reviews.raw(review_id)
scores = [sia.polarity_scores(sentence)["compound"]
for sentence in nltk.sent_tokenize(text) ]
meanscore = mean(scores)
if threshold<0 or threshold>1:
threshold = 0 #default
if meanscore > threshold:
return 'positive'
elif meanscore <-threshold:
return 'negative'
else:
return 'neutral'
#let's compare VADER to human labels of the movie reviews
for threshold in [0,0.025, 0.05, 0.1,0.125, 0.15, 0.2]:
correct = 0
neutral = 0
for review_id in sample_review_ids:
if meansentiment(review_id, threshold)=='positive':
if review_id in positive_review_ids:
correct += 1
elif meansentiment(review_id, threshold)=='negative':
if review_id in negative_review_ids:
correct += 1
else:
#if neutral, then it is too ambiguous to classify by VADER
#so we will drop the case from the evaluation
neutral +=1
print(F"At threshold = {threshold}; {correct / (len(sample_review_ids)-neutral):.2%} correct")
print(F"At threshold = {threshold}; {neutral} reviews were too ambiguous.")
[nltk_data] Downloading package movie_reviews to
[nltk_data] C:\Users\apalangkaraya\AppData\Roaming\nltk_data...
[nltk_data] Package movie_reviews is already up-to-date!
['neg/cv000_29416.txt', 'neg/cv001_19502.txt', 'neg/cv002_17424.txt', 'neg/cv003_12683.txt', 'neg/cv004_12641.txt', 'neg/cv005_29357.txt', 'neg/cv006_17022.txt', 'neg/cv007_4992.txt', 'neg/cv008_29326.txt', 'neg/cv009_29417.txt', 'neg/cv010_29063.txt', 'neg/cv011_13044.txt', 'neg/cv012_29411.txt', 'neg/cv013_10494.txt', 'neg/cv014_15600.txt', 'neg/cv015_29356.txt', 'neg/cv016_4348.txt', 'neg/cv017_23487.txt', 'neg/cv018_21672.txt', 'neg/cv019_16117.txt', 'neg/cv020_9234.txt', 'neg/cv021_17313.txt', 'neg/cv022_14227.txt', 'neg/cv023_13847.txt', 'neg/cv024_7033.txt', 'neg/cv025_29825.txt', 'neg/cv026_29229.txt', 'neg/cv027_26270.txt', 'neg/cv028_26964.txt', 'neg/cv029_19943.txt', 'neg/cv030_22893.txt', 'neg/cv031_19540.txt', 'neg/cv032_23718.txt', 'neg/cv033_25680.txt', 'neg/cv034_29446.txt', 'neg/cv035_3343.txt', 'neg/cv036_18385.txt', 'neg/cv037_19798.txt', 'neg/cv038_9781.txt', 'neg/cv039_5963.txt', 'neg/cv040_8829.txt', 'neg/cv041_22364.txt', 'neg/cv042_11927.txt', 'neg/cv043_16808.txt', 'neg/cv044_18429.txt', 'neg/cv045_25077.txt', 'neg/cv046_10613.txt', 'neg/cv047_18725.txt', 'neg/cv048_18380.txt', 'neg/cv049_21917.txt', 'neg/cv050_12128.txt', 'neg/cv051_10751.txt', 'neg/cv052_29318.txt', 'neg/cv053_23117.txt', 'neg/cv054_4101.txt', 'neg/cv055_8926.txt', 'neg/cv056_14663.txt', 'neg/cv057_7962.txt', 'neg/cv058_8469.txt', 'neg/cv059_28723.txt', 'neg/cv060_11754.txt', 'neg/cv061_9321.txt', 'neg/cv062_24556.txt', 'neg/cv063_28852.txt', 'neg/cv064_25842.txt', 'neg/cv065_16909.txt', 'neg/cv066_11668.txt', 'neg/cv067_21192.txt', 'neg/cv068_14810.txt', 'neg/cv069_11613.txt', 'neg/cv070_13249.txt', 'neg/cv071_12969.txt', 'neg/cv072_5928.txt', 'neg/cv073_23039.txt', 'neg/cv074_7188.txt', 'neg/cv075_6250.txt', 'neg/cv076_26009.txt', 'neg/cv077_23172.txt', 'neg/cv078_16506.txt', 'neg/cv079_12766.txt', 'neg/cv080_14899.txt', 'neg/cv081_18241.txt', 'neg/cv082_11979.txt', 'neg/cv083_25491.txt', 'neg/cv084_15183.txt', 'neg/cv085_15286.txt', 'neg/cv086_19488.txt', 'neg/cv087_2145.txt', 'neg/cv088_25274.txt', 'neg/cv089_12222.txt', 'neg/cv090_0049.txt', 'neg/cv091_7899.txt', 'neg/cv092_27987.txt', 'neg/cv093_15606.txt', 'neg/cv094_27868.txt', 'neg/cv095_28730.txt', 'neg/cv096_12262.txt', 'neg/cv097_26081.txt', 'neg/cv098_17021.txt', 'neg/cv099_11189.txt', 'neg/cv100_12406.txt', 'neg/cv101_10537.txt', 'neg/cv102_8306.txt', 'neg/cv103_11943.txt', 'neg/cv104_19176.txt', 'neg/cv105_19135.txt', 'neg/cv106_18379.txt', 'neg/cv107_25639.txt', 'neg/cv108_17064.txt', 'neg/cv109_22599.txt', 'neg/cv110_27832.txt', 'neg/cv111_12253.txt', 'neg/cv112_12178.txt', 'neg/cv113_24354.txt', 'neg/cv114_19501.txt', 'neg/cv115_26443.txt', 'neg/cv116_28734.txt', 'neg/cv117_25625.txt', 'neg/cv118_28837.txt', 'neg/cv119_9909.txt', 'neg/cv120_3793.txt', 'neg/cv121_18621.txt', 'neg/cv122_7891.txt', 'neg/cv123_12165.txt', 'neg/cv124_3903.txt', 'neg/cv125_9636.txt', 'neg/cv126_28821.txt', 'neg/cv127_16451.txt', 'neg/cv128_29444.txt', 'neg/cv129_18373.txt', 'neg/cv130_18521.txt', 'neg/cv131_11568.txt', 'neg/cv132_5423.txt', 'neg/cv133_18065.txt', 'neg/cv134_23300.txt', 'neg/cv135_12506.txt', 'neg/cv136_12384.txt', 'neg/cv137_17020.txt', 'neg/cv138_13903.txt', 'neg/cv139_14236.txt', 'neg/cv140_7963.txt', 'neg/cv141_17179.txt', 'neg/cv142_23657.txt', 'neg/cv143_21158.txt', 'neg/cv144_5010.txt', 'neg/cv145_12239.txt', 'neg/cv146_19587.txt', 'neg/cv147_22625.txt', 'neg/cv148_18084.txt', 'neg/cv149_17084.txt', 'neg/cv150_14279.txt', 'neg/cv151_17231.txt', 'neg/cv152_9052.txt', 'neg/cv153_11607.txt', 'neg/cv154_9562.txt', 'neg/cv155_7845.txt', 'neg/cv156_11119.txt', 'neg/cv157_29302.txt', 'neg/cv158_10914.txt', 'neg/cv159_29374.txt', 'neg/cv160_10848.txt', 'neg/cv161_12224.txt', 'neg/cv162_10977.txt', 'neg/cv163_10110.txt', 'neg/cv164_23451.txt', 'neg/cv165_2389.txt', 'neg/cv166_11959.txt', 'neg/cv167_18094.txt', 'neg/cv168_7435.txt', 'neg/cv169_24973.txt', 'neg/cv170_29808.txt', 'neg/cv171_15164.txt', 'neg/cv172_12037.txt', 'neg/cv173_4295.txt', 'neg/cv174_9735.txt', 'neg/cv175_7375.txt', 'neg/cv176_14196.txt', 'neg/cv177_10904.txt', 'neg/cv178_14380.txt', 'neg/cv179_9533.txt', 'neg/cv180_17823.txt', 'neg/cv181_16083.txt', 'neg/cv182_7791.txt', 'neg/cv183_19826.txt', 'neg/cv184_26935.txt', 'neg/cv185_28372.txt', 'neg/cv186_2396.txt', 'neg/cv187_14112.txt', 'neg/cv188_20687.txt', 'neg/cv189_24248.txt', 'neg/cv190_27176.txt', 'neg/cv191_29539.txt', 'neg/cv192_16079.txt', 'neg/cv193_5393.txt', 'neg/cv194_12855.txt', 'neg/cv195_16146.txt', 'neg/cv196_28898.txt', 'neg/cv197_29271.txt', 'neg/cv198_19313.txt', 'neg/cv199_9721.txt', 'neg/cv200_29006.txt', 'neg/cv201_7421.txt', 'neg/cv202_11382.txt', 'neg/cv203_19052.txt', 'neg/cv204_8930.txt', 'neg/cv205_9676.txt', 'neg/cv206_15893.txt', 'neg/cv207_29141.txt', 'neg/cv208_9475.txt', 'neg/cv209_28973.txt', 'neg/cv210_9557.txt', 'neg/cv211_9955.txt', 'neg/cv212_10054.txt', 'neg/cv213_20300.txt', 'neg/cv214_13285.txt', 'neg/cv215_23246.txt', 'neg/cv216_20165.txt', 'neg/cv217_28707.txt', 'neg/cv218_25651.txt', 'neg/cv219_19874.txt', 'neg/cv220_28906.txt', 'neg/cv221_27081.txt', 'neg/cv222_18720.txt', 'neg/cv223_28923.txt', 'neg/cv224_18875.txt', 'neg/cv225_29083.txt', 'neg/cv226_26692.txt', 'neg/cv227_25406.txt', 'neg/cv228_5644.txt', 'neg/cv229_15200.txt', 'neg/cv230_7913.txt', 'neg/cv231_11028.txt', 'neg/cv232_16768.txt', 'neg/cv233_17614.txt', 'neg/cv234_22123.txt', 'neg/cv235_10704.txt', 'neg/cv236_12427.txt', 'neg/cv237_20635.txt', 'neg/cv238_14285.txt', 'neg/cv239_29828.txt', 'neg/cv240_15948.txt', 'neg/cv241_24602.txt', 'neg/cv242_11354.txt', 'neg/cv243_22164.txt', 'neg/cv244_22935.txt', 'neg/cv245_8938.txt', 'neg/cv246_28668.txt', 'neg/cv247_14668.txt', 'neg/cv248_15672.txt', 'neg/cv249_12674.txt', 'neg/cv250_26462.txt', 'neg/cv251_23901.txt', 'neg/cv252_24974.txt', 'neg/cv253_10190.txt', 'neg/cv254_5870.txt', 'neg/cv255_15267.txt', 'neg/cv256_16529.txt', 'neg/cv257_11856.txt', 'neg/cv258_5627.txt', 'neg/cv259_11827.txt', 'neg/cv260_15652.txt', 'neg/cv261_11855.txt', 'neg/cv262_13812.txt', 'neg/cv263_20693.txt', 'neg/cv264_14108.txt', 'neg/cv265_11625.txt', 'neg/cv266_26644.txt', 'neg/cv267_16618.txt', 'neg/cv268_20288.txt', 'neg/cv269_23018.txt', 'neg/cv270_5873.txt', 'neg/cv271_15364.txt', 'neg/cv272_20313.txt', 'neg/cv273_28961.txt', 'neg/cv274_26379.txt', 'neg/cv275_28725.txt', 'neg/cv276_17126.txt', 'neg/cv277_20467.txt', 'neg/cv278_14533.txt', 'neg/cv279_19452.txt', 'neg/cv280_8651.txt', 'neg/cv281_24711.txt', 'neg/cv282_6833.txt', 'neg/cv283_11963.txt', 'neg/cv284_20530.txt', 'neg/cv285_18186.txt', 'neg/cv286_26156.txt', 'neg/cv287_17410.txt', 'neg/cv288_20212.txt', 'neg/cv289_6239.txt', 'neg/cv290_11981.txt', 'neg/cv291_26844.txt', 'neg/cv292_7804.txt', 'neg/cv293_29731.txt', 'neg/cv294_12695.txt', 'neg/cv295_17060.txt', 'neg/cv296_13146.txt', 'neg/cv297_10104.txt', 'neg/cv298_24487.txt', 'neg/cv299_17950.txt', 'neg/cv300_23302.txt', 'neg/cv301_13010.txt', 'neg/cv302_26481.txt', 'neg/cv303_27366.txt', 'neg/cv304_28489.txt', 'neg/cv305_9937.txt', 'neg/cv306_10859.txt', 'neg/cv307_26382.txt', 'neg/cv308_5079.txt', 'neg/cv309_23737.txt', 'neg/cv310_14568.txt', 'neg/cv311_17708.txt', 'neg/cv312_29308.txt', 'neg/cv313_19337.txt', 'neg/cv314_16095.txt', 'neg/cv315_12638.txt', 'neg/cv316_5972.txt', 'neg/cv317_25111.txt', 'neg/cv318_11146.txt', 'neg/cv319_16459.txt', 'neg/cv320_9693.txt', 'neg/cv321_14191.txt', 'neg/cv322_21820.txt', 'neg/cv323_29633.txt', 'neg/cv324_7502.txt', 'neg/cv325_18330.txt', 'neg/cv326_14777.txt', 'neg/cv327_21743.txt', 'neg/cv328_10908.txt', 'neg/cv329_29293.txt', 'neg/cv330_29675.txt', 'neg/cv331_8656.txt', 'neg/cv332_17997.txt', 'neg/cv333_9443.txt', 'neg/cv334_0074.txt', 'neg/cv335_16299.txt', 'neg/cv336_10363.txt', 'neg/cv337_29061.txt', 'neg/cv338_9183.txt', 'neg/cv339_22452.txt', 'neg/cv340_14776.txt', 'neg/cv341_25667.txt', 'neg/cv342_20917.txt', 'neg/cv343_10906.txt', 'neg/cv344_5376.txt', 'neg/cv345_9966.txt', 'neg/cv346_19198.txt', 'neg/cv347_14722.txt', 'neg/cv348_19207.txt', 'neg/cv349_15032.txt', 'neg/cv350_22139.txt', 'neg/cv351_17029.txt', 'neg/cv352_5414.txt', 'neg/cv353_19197.txt', 'neg/cv354_8573.txt', 'neg/cv355_18174.txt', 'neg/cv356_26170.txt', 'neg/cv357_14710.txt', 'neg/cv358_11557.txt', 'neg/cv359_6751.txt', 'neg/cv360_8927.txt', 'neg/cv361_28738.txt', 'neg/cv362_16985.txt', 'neg/cv363_29273.txt', 'neg/cv364_14254.txt', 'neg/cv365_12442.txt', 'neg/cv366_10709.txt', 'neg/cv367_24065.txt', 'neg/cv368_11090.txt', 'neg/cv369_14245.txt', 'neg/cv370_5338.txt', 'neg/cv371_8197.txt', 'neg/cv372_6654.txt', 'neg/cv373_21872.txt', 'neg/cv374_26455.txt', 'neg/cv375_9932.txt', 'neg/cv376_20883.txt', 'neg/cv377_8440.txt', 'neg/cv378_21982.txt', 'neg/cv379_23167.txt', 'neg/cv380_8164.txt', 'neg/cv381_21673.txt', 'neg/cv382_8393.txt', 'neg/cv383_14662.txt', 'neg/cv384_18536.txt', 'neg/cv385_29621.txt', 'neg/cv386_10229.txt', 'neg/cv387_12391.txt', 'neg/cv388_12810.txt', 'neg/cv389_9611.txt', 'neg/cv390_12187.txt', 'neg/cv391_11615.txt', 'neg/cv392_12238.txt', 'neg/cv393_29234.txt', 'neg/cv394_5311.txt', 'neg/cv395_11761.txt', 'neg/cv396_19127.txt', 'neg/cv397_28890.txt', 'neg/cv398_17047.txt', 'neg/cv399_28593.txt', 'neg/cv400_20631.txt', 'neg/cv401_13758.txt', 'neg/cv402_16097.txt', 'neg/cv403_6721.txt', 'neg/cv404_21805.txt', 'neg/cv405_21868.txt', 'neg/cv406_22199.txt', 'neg/cv407_23928.txt', 'neg/cv408_5367.txt', 'neg/cv409_29625.txt', 'neg/cv410_25624.txt', 'neg/cv411_16799.txt', 'neg/cv412_25254.txt', 'neg/cv413_7893.txt', 'neg/cv414_11161.txt', 'neg/cv415_23674.txt', 'neg/cv416_12048.txt', 'neg/cv417_14653.txt', 'neg/cv418_16562.txt', 'neg/cv419_14799.txt', 'neg/cv420_28631.txt', 'neg/cv421_9752.txt', 'neg/cv422_9632.txt', 'neg/cv423_12089.txt', 'neg/cv424_9268.txt', 'neg/cv425_8603.txt', 'neg/cv426_10976.txt', 'neg/cv427_11693.txt', 'neg/cv428_12202.txt', 'neg/cv429_7937.txt', 'neg/cv430_18662.txt', 'neg/cv431_7538.txt', 'neg/cv432_15873.txt', 'neg/cv433_10443.txt', 'neg/cv434_5641.txt', 'neg/cv435_24355.txt', 'neg/cv436_20564.txt', 'neg/cv437_24070.txt', 'neg/cv438_8500.txt', 'neg/cv439_17633.txt', 'neg/cv440_16891.txt', 'neg/cv441_15276.txt', 'neg/cv442_15499.txt', 'neg/cv443_22367.txt', 'neg/cv444_9975.txt', 'neg/cv445_26683.txt', 'neg/cv446_12209.txt', 'neg/cv447_27334.txt', 'neg/cv448_16409.txt', 'neg/cv449_9126.txt', 'neg/cv450_8319.txt', 'neg/cv451_11502.txt', 'neg/cv452_5179.txt', 'neg/cv453_10911.txt', 'neg/cv454_21961.txt', 'neg/cv455_28866.txt', 'neg/cv456_20370.txt', 'neg/cv457_19546.txt', 'neg/cv458_9000.txt', 'neg/cv459_21834.txt', 'neg/cv460_11723.txt', 'neg/cv461_21124.txt', 'neg/cv462_20788.txt', 'neg/cv463_10846.txt', 'neg/cv464_17076.txt', 'neg/cv465_23401.txt', 'neg/cv466_20092.txt', 'neg/cv467_26610.txt', 'neg/cv468_16844.txt', 'neg/cv469_21998.txt', 'neg/cv470_17444.txt', 'neg/cv471_18405.txt', 'neg/cv472_29140.txt', 'neg/cv473_7869.txt', 'neg/cv474_10682.txt', 'neg/cv475_22978.txt', 'neg/cv476_18402.txt', 'neg/cv477_23530.txt', 'neg/cv478_15921.txt', 'neg/cv479_5450.txt', 'neg/cv480_21195.txt', 'neg/cv481_7930.txt', 'neg/cv482_11233.txt', 'neg/cv483_18103.txt', 'neg/cv484_26169.txt', 'neg/cv485_26879.txt', 'neg/cv486_9788.txt', 'neg/cv487_11058.txt', 'neg/cv488_21453.txt', 'neg/cv489_19046.txt', 'neg/cv490_18986.txt', 'neg/cv491_12992.txt', 'neg/cv492_19370.txt', 'neg/cv493_14135.txt', 'neg/cv494_18689.txt', 'neg/cv495_16121.txt', 'neg/cv496_11185.txt', 'neg/cv497_27086.txt', 'neg/cv498_9288.txt', 'neg/cv499_11407.txt', 'neg/cv500_10722.txt', 'neg/cv501_12675.txt', 'neg/cv502_10970.txt', 'neg/cv503_11196.txt', 'neg/cv504_29120.txt', 'neg/cv505_12926.txt', 'neg/cv506_17521.txt', 'neg/cv507_9509.txt', 'neg/cv508_17742.txt', 'neg/cv509_17354.txt', 'neg/cv510_24758.txt', 'neg/cv511_10360.txt', 'neg/cv512_17618.txt', 'neg/cv513_7236.txt', 'neg/cv514_12173.txt', 'neg/cv515_18484.txt', 'neg/cv516_12117.txt', 'neg/cv517_20616.txt', 'neg/cv518_14798.txt', 'neg/cv519_16239.txt', 'neg/cv520_13297.txt', 'neg/cv521_1730.txt', 'neg/cv522_5418.txt', 'neg/cv523_18285.txt', 'neg/cv524_24885.txt', 'neg/cv525_17930.txt', 'neg/cv526_12868.txt', 'neg/cv527_10338.txt', 'neg/cv528_11669.txt', 'neg/cv529_10972.txt', 'neg/cv530_17949.txt', 'neg/cv531_26838.txt', 'neg/cv532_6495.txt', 'neg/cv533_9843.txt', 'neg/cv534_15683.txt', 'neg/cv535_21183.txt', 'neg/cv536_27221.txt', 'neg/cv537_13516.txt', 'neg/cv538_28485.txt', 'neg/cv539_21865.txt', 'neg/cv540_3092.txt', 'neg/cv541_28683.txt', 'neg/cv542_20359.txt', 'neg/cv543_5107.txt', 'neg/cv544_5301.txt', 'neg/cv545_12848.txt', 'neg/cv546_12723.txt', 'neg/cv547_18043.txt', 'neg/cv548_18944.txt', 'neg/cv549_22771.txt', 'neg/cv550_23226.txt', 'neg/cv551_11214.txt', 'neg/cv552_0150.txt', 'neg/cv553_26965.txt', 'neg/cv554_14678.txt', 'neg/cv555_25047.txt', 'neg/cv556_16563.txt', 'neg/cv557_12237.txt', 'neg/cv558_29376.txt', 'neg/cv559_0057.txt', 'neg/cv560_18608.txt', 'neg/cv561_9484.txt', 'neg/cv562_10847.txt', 'neg/cv563_18610.txt', 'neg/cv564_12011.txt', 'neg/cv565_29403.txt', 'neg/cv566_8967.txt', 'neg/cv567_29420.txt', 'neg/cv568_17065.txt', 'neg/cv569_26750.txt', 'neg/cv570_28960.txt', 'neg/cv571_29292.txt', 'neg/cv572_20053.txt', 'neg/cv573_29384.txt', 'neg/cv574_23191.txt', 'neg/cv575_22598.txt', 'neg/cv576_15688.txt', 'neg/cv577_28220.txt', 'neg/cv578_16825.txt', 'neg/cv579_12542.txt', 'neg/cv580_15681.txt', 'neg/cv581_20790.txt', 'neg/cv582_6678.txt', 'neg/cv583_29465.txt', 'neg/cv584_29549.txt', 'neg/cv585_23576.txt', 'neg/cv586_8048.txt', 'neg/cv587_20532.txt', 'neg/cv588_14467.txt', 'neg/cv589_12853.txt', 'neg/cv590_20712.txt', 'neg/cv591_24887.txt', 'neg/cv592_23391.txt', 'neg/cv593_11931.txt', 'neg/cv594_11945.txt', 'neg/cv595_26420.txt', 'neg/cv596_4367.txt', 'neg/cv597_26744.txt', 'neg/cv598_18184.txt', 'neg/cv599_22197.txt', 'neg/cv600_25043.txt', 'neg/cv601_24759.txt', 'neg/cv602_8830.txt', 'neg/cv603_18885.txt', 'neg/cv604_23339.txt', 'neg/cv605_12730.txt', 'neg/cv606_17672.txt', 'neg/cv607_8235.txt', 'neg/cv608_24647.txt', 'neg/cv609_25038.txt', 'neg/cv610_24153.txt', 'neg/cv611_2253.txt', 'neg/cv612_5396.txt', 'neg/cv613_23104.txt', 'neg/cv614_11320.txt', 'neg/cv615_15734.txt', 'neg/cv616_29187.txt', 'neg/cv617_9561.txt', 'neg/cv618_9469.txt', 'neg/cv619_13677.txt', 'neg/cv620_2556.txt', 'neg/cv621_15984.txt', 'neg/cv622_8583.txt', 'neg/cv623_16988.txt', 'neg/cv624_11601.txt', 'neg/cv625_13518.txt', 'neg/cv626_7907.txt', 'neg/cv627_12603.txt', 'neg/cv628_20758.txt', 'neg/cv629_16604.txt', 'neg/cv630_10152.txt', 'neg/cv631_4782.txt', 'neg/cv632_9704.txt', 'neg/cv633_29730.txt', 'neg/cv634_11989.txt', 'neg/cv635_0984.txt', 'neg/cv636_16954.txt', 'neg/cv637_13682.txt', 'neg/cv638_29394.txt', 'neg/cv639_10797.txt', 'neg/cv640_5380.txt', 'neg/cv641_13412.txt', 'neg/cv642_29788.txt', 'neg/cv643_29282.txt', 'neg/cv644_18551.txt', 'neg/cv645_17078.txt', 'neg/cv646_16817.txt', 'neg/cv647_15275.txt', 'neg/cv648_17277.txt', 'neg/cv649_13947.txt', 'neg/cv650_15974.txt', 'neg/cv651_11120.txt', 'neg/cv652_15653.txt', 'neg/cv653_2107.txt', 'neg/cv654_19345.txt', 'neg/cv655_12055.txt', 'neg/cv656_25395.txt', 'neg/cv657_25835.txt', 'neg/cv658_11186.txt', 'neg/cv659_21483.txt', 'neg/cv660_23140.txt', 'neg/cv661_25780.txt', 'neg/cv662_14791.txt', 'neg/cv663_14484.txt', 'neg/cv664_4264.txt', 'neg/cv665_29386.txt', 'neg/cv666_20301.txt', 'neg/cv667_19672.txt', 'neg/cv668_18848.txt', 'neg/cv669_24318.txt', 'neg/cv670_2666.txt', 'neg/cv671_5164.txt', 'neg/cv672_27988.txt', 'neg/cv673_25874.txt', 'neg/cv674_11593.txt', 'neg/cv675_22871.txt', 'neg/cv676_22202.txt', 'neg/cv677_18938.txt', 'neg/cv678_14887.txt', 'neg/cv679_28221.txt', 'neg/cv680_10533.txt', 'neg/cv681_9744.txt', 'neg/cv682_17947.txt', 'neg/cv683_13047.txt', 'neg/cv684_12727.txt', 'neg/cv685_5710.txt', 'neg/cv686_15553.txt', 'neg/cv687_22207.txt', 'neg/cv688_7884.txt', 'neg/cv689_13701.txt', 'neg/cv690_5425.txt', 'neg/cv691_5090.txt', 'neg/cv692_17026.txt', 'neg/cv693_19147.txt', 'neg/cv694_4526.txt', 'neg/cv695_22268.txt', 'neg/cv696_29619.txt', 'neg/cv697_12106.txt', 'neg/cv698_16930.txt', 'neg/cv699_7773.txt', 'neg/cv700_23163.txt', 'neg/cv701_15880.txt', 'neg/cv702_12371.txt', 'neg/cv703_17948.txt', 'neg/cv704_17622.txt', 'neg/cv705_11973.txt', 'neg/cv706_25883.txt', 'neg/cv707_11421.txt', 'neg/cv708_28539.txt', 'neg/cv709_11173.txt', 'neg/cv710_23745.txt', 'neg/cv711_12687.txt', 'neg/cv712_24217.txt', 'neg/cv713_29002.txt', 'neg/cv714_19704.txt', 'neg/cv715_19246.txt', 'neg/cv716_11153.txt', 'neg/cv717_17472.txt', 'neg/cv718_12227.txt', 'neg/cv719_5581.txt', 'neg/cv720_5383.txt', 'neg/cv721_28993.txt', 'neg/cv722_7571.txt', 'neg/cv723_9002.txt', 'neg/cv724_15265.txt', 'neg/cv725_10266.txt', 'neg/cv726_4365.txt', 'neg/cv727_5006.txt', 'neg/cv728_17931.txt', 'neg/cv729_10475.txt', 'neg/cv730_10729.txt', 'neg/cv731_3968.txt', 'neg/cv732_13092.txt', 'neg/cv733_9891.txt', 'neg/cv734_22821.txt', 'neg/cv735_20218.txt', 'neg/cv736_24947.txt', 'neg/cv737_28733.txt', 'neg/cv738_10287.txt', 'neg/cv739_12179.txt', 'neg/cv740_13643.txt', 'neg/cv741_12765.txt', 'neg/cv742_8279.txt', 'neg/cv743_17023.txt', 'neg/cv744_10091.txt', 'neg/cv745_14009.txt', 'neg/cv746_10471.txt', 'neg/cv747_18189.txt', 'neg/cv748_14044.txt', 'neg/cv749_18960.txt', 'neg/cv750_10606.txt', 'neg/cv751_17208.txt', 'neg/cv752_25330.txt', 'neg/cv753_11812.txt', 'neg/cv754_7709.txt', 'neg/cv755_24881.txt', 'neg/cv756_23676.txt', 'neg/cv757_10668.txt', 'neg/cv758_9740.txt', 'neg/cv759_15091.txt', 'neg/cv760_8977.txt', 'neg/cv761_13769.txt', 'neg/cv762_15604.txt', 'neg/cv763_16486.txt', 'neg/cv764_12701.txt', 'neg/cv765_20429.txt', 'neg/cv766_7983.txt', 'neg/cv767_15673.txt', 'neg/cv768_12709.txt', 'neg/cv769_8565.txt', 'neg/cv770_11061.txt', 'neg/cv771_28466.txt', 'neg/cv772_12971.txt', 'neg/cv773_20264.txt', 'neg/cv774_15488.txt', 'neg/cv775_17966.txt', 'neg/cv776_21934.txt', 'neg/cv777_10247.txt', 'neg/cv778_18629.txt', 'neg/cv779_18989.txt', 'neg/cv780_8467.txt', 'neg/cv781_5358.txt', 'neg/cv782_21078.txt', 'neg/cv783_14724.txt', 'neg/cv784_16077.txt', 'neg/cv785_23748.txt', 'neg/cv786_23608.txt', 'neg/cv787_15277.txt', 'neg/cv788_26409.txt', 'neg/cv789_12991.txt', 'neg/cv790_16202.txt', 'neg/cv791_17995.txt', 'neg/cv792_3257.txt', 'neg/cv793_15235.txt', 'neg/cv794_17353.txt', 'neg/cv795_10291.txt', 'neg/cv796_17243.txt', 'neg/cv797_7245.txt', 'neg/cv798_24779.txt', 'neg/cv799_19812.txt', 'neg/cv800_13494.txt', 'neg/cv801_26335.txt', 'neg/cv802_28381.txt', 'neg/cv803_8584.txt', 'neg/cv804_11763.txt', 'neg/cv805_21128.txt', 'neg/cv806_9405.txt', 'neg/cv807_23024.txt', 'neg/cv808_13773.txt', 'neg/cv809_5012.txt', 'neg/cv810_13660.txt', 'neg/cv811_22646.txt', 'neg/cv812_19051.txt', 'neg/cv813_6649.txt', 'neg/cv814_20316.txt', 'neg/cv815_23466.txt', 'neg/cv816_15257.txt', 'neg/cv817_3675.txt', 'neg/cv818_10698.txt', 'neg/cv819_9567.txt', 'neg/cv820_24157.txt', 'neg/cv821_29283.txt', 'neg/cv822_21545.txt', 'neg/cv823_17055.txt', 'neg/cv824_9335.txt', 'neg/cv825_5168.txt', 'neg/cv826_12761.txt', 'neg/cv827_19479.txt', 'neg/cv828_21392.txt', 'neg/cv829_21725.txt', 'neg/cv830_5778.txt', 'neg/cv831_16325.txt', 'neg/cv832_24713.txt', 'neg/cv833_11961.txt', 'neg/cv834_23192.txt', 'neg/cv835_20531.txt', 'neg/cv836_14311.txt', 'neg/cv837_27232.txt', 'neg/cv838_25886.txt', 'neg/cv839_22807.txt', 'neg/cv840_18033.txt', 'neg/cv841_3367.txt', 'neg/cv842_5702.txt', 'neg/cv843_17054.txt', 'neg/cv844_13890.txt', 'neg/cv845_15886.txt', 'neg/cv846_29359.txt', 'neg/cv847_20855.txt', 'neg/cv848_10061.txt', 'neg/cv849_17215.txt', 'neg/cv850_18185.txt', 'neg/cv851_21895.txt', 'neg/cv852_27512.txt', 'neg/cv853_29119.txt', 'neg/cv854_18955.txt', 'neg/cv855_22134.txt', 'neg/cv856_28882.txt', 'neg/cv857_17527.txt', 'neg/cv858_20266.txt', 'neg/cv859_15689.txt', 'neg/cv860_15520.txt', 'neg/cv861_12809.txt', 'neg/cv862_15924.txt', 'neg/cv863_7912.txt', 'neg/cv864_3087.txt', 'neg/cv865_28796.txt', 'neg/cv866_29447.txt', 'neg/cv867_18362.txt', 'neg/cv868_12799.txt', 'neg/cv869_24782.txt', 'neg/cv870_18090.txt', 'neg/cv871_25971.txt', 'neg/cv872_13710.txt', 'neg/cv873_19937.txt', 'neg/cv874_12182.txt', 'neg/cv875_5622.txt', 'neg/cv876_9633.txt', 'neg/cv877_29132.txt', 'neg/cv878_17204.txt', 'neg/cv879_16585.txt', 'neg/cv880_29629.txt', 'neg/cv881_14767.txt', 'neg/cv882_10042.txt', 'neg/cv883_27621.txt', 'neg/cv884_15230.txt', 'neg/cv885_13390.txt', 'neg/cv886_19210.txt', 'neg/cv887_5306.txt', 'neg/cv888_25678.txt', 'neg/cv889_22670.txt', 'neg/cv890_3515.txt', 'neg/cv891_6035.txt', 'neg/cv892_18788.txt', 'neg/cv893_26731.txt', 'neg/cv894_22140.txt', 'neg/cv895_22200.txt', 'neg/cv896_17819.txt', 'neg/cv897_11703.txt', 'neg/cv898_1576.txt', 'neg/cv899_17812.txt', 'neg/cv900_10800.txt', 'neg/cv901_11934.txt', 'neg/cv902_13217.txt', 'neg/cv903_18981.txt', 'neg/cv904_25663.txt', 'neg/cv905_28965.txt', 'neg/cv906_12332.txt', 'neg/cv907_3193.txt', 'neg/cv908_17779.txt', 'neg/cv909_9973.txt', 'neg/cv910_21930.txt', 'neg/cv911_21695.txt', 'neg/cv912_5562.txt', 'neg/cv913_29127.txt', 'neg/cv914_2856.txt', 'neg/cv915_9342.txt', 'neg/cv916_17034.txt', 'neg/cv917_29484.txt', 'neg/cv918_27080.txt', 'neg/cv919_18155.txt', 'neg/cv920_29423.txt', 'neg/cv921_13988.txt', 'neg/cv922_10185.txt', 'neg/cv923_11951.txt', 'neg/cv924_29397.txt', 'neg/cv925_9459.txt', 'neg/cv926_18471.txt', 'neg/cv927_11471.txt', 'neg/cv928_9478.txt', 'neg/cv929_1841.txt', 'neg/cv930_14949.txt', 'neg/cv931_18783.txt', 'neg/cv932_14854.txt', 'neg/cv933_24953.txt', 'neg/cv934_20426.txt', 'neg/cv935_24977.txt', 'neg/cv936_17473.txt', 'neg/cv937_9816.txt', 'neg/cv938_10706.txt', 'neg/cv939_11247.txt', 'neg/cv940_18935.txt', 'neg/cv941_10718.txt', 'neg/cv942_18509.txt', 'neg/cv943_23547.txt', 'neg/cv944_15042.txt', 'neg/cv945_13012.txt', 'neg/cv946_20084.txt', 'neg/cv947_11316.txt', 'neg/cv948_25870.txt', 'neg/cv949_21565.txt', 'neg/cv950_13478.txt', 'neg/cv951_11816.txt', 'neg/cv952_26375.txt', 'neg/cv953_7078.txt', 'neg/cv954_19932.txt', 'neg/cv955_26154.txt', 'neg/cv956_12547.txt', 'neg/cv957_9059.txt', 'neg/cv958_13020.txt', 'neg/cv959_16218.txt', 'neg/cv960_28877.txt', 'neg/cv961_5578.txt', 'neg/cv962_9813.txt', 'neg/cv963_7208.txt', 'neg/cv964_5794.txt', 'neg/cv965_26688.txt', 'neg/cv966_28671.txt', 'neg/cv967_5626.txt', 'neg/cv968_25413.txt', 'neg/cv969_14760.txt', 'neg/cv970_19532.txt', 'neg/cv971_11790.txt', 'neg/cv972_26837.txt', 'neg/cv973_10171.txt', 'neg/cv974_24303.txt', 'neg/cv975_11920.txt', 'neg/cv976_10724.txt', 'neg/cv977_4776.txt', 'neg/cv978_22192.txt', 'neg/cv979_2029.txt', 'neg/cv980_11851.txt', 'neg/cv981_16679.txt', 'neg/cv982_22209.txt', 'neg/cv983_24219.txt', 'neg/cv984_14006.txt', 'neg/cv985_5964.txt', 'neg/cv986_15092.txt', 'neg/cv987_7394.txt', 'neg/cv988_20168.txt', 'neg/cv989_17297.txt', 'neg/cv990_12443.txt', 'neg/cv991_19973.txt', 'neg/cv992_12806.txt', 'neg/cv993_29565.txt', 'neg/cv994_13229.txt', 'neg/cv995_23113.txt', 'neg/cv996_12447.txt', 'neg/cv997_5152.txt', 'neg/cv998_15691.txt', 'neg/cv999_14636.txt', 'pos/cv000_29590.txt', 'pos/cv001_18431.txt', 'pos/cv002_15918.txt', 'pos/cv003_11664.txt', 'pos/cv004_11636.txt', 'pos/cv005_29443.txt', 'pos/cv006_15448.txt', 'pos/cv007_4968.txt', 'pos/cv008_29435.txt', 'pos/cv009_29592.txt', 'pos/cv010_29198.txt', 'pos/cv011_12166.txt', 'pos/cv012_29576.txt', 'pos/cv013_10159.txt', 'pos/cv014_13924.txt', 'pos/cv015_29439.txt', 'pos/cv016_4659.txt', 'pos/cv017_22464.txt', 'pos/cv018_20137.txt', 'pos/cv019_14482.txt', 'pos/cv020_8825.txt', 'pos/cv021_15838.txt', 'pos/cv022_12864.txt', 'pos/cv023_12672.txt', 'pos/cv024_6778.txt', 'pos/cv025_3108.txt', 'pos/cv026_29325.txt', 'pos/cv027_25219.txt', 'pos/cv028_26746.txt', 'pos/cv029_18643.txt', 'pos/cv030_21593.txt', 'pos/cv031_18452.txt', 'pos/cv032_22550.txt', 'pos/cv033_24444.txt', 'pos/cv034_29647.txt', 'pos/cv035_3954.txt', 'pos/cv036_16831.txt', 'pos/cv037_18510.txt', 'pos/cv038_9749.txt', 'pos/cv039_6170.txt', 'pos/cv040_8276.txt', 'pos/cv041_21113.txt', 'pos/cv042_10982.txt', 'pos/cv043_15013.txt', 'pos/cv044_16969.txt', 'pos/cv045_23923.txt', 'pos/cv046_10188.txt', 'pos/cv047_1754.txt', 'pos/cv048_16828.txt', 'pos/cv049_20471.txt', 'pos/cv050_11175.txt', 'pos/cv051_10306.txt', 'pos/cv052_29378.txt', 'pos/cv053_21822.txt', 'pos/cv054_4230.txt', 'pos/cv055_8338.txt', 'pos/cv056_13133.txt', 'pos/cv057_7453.txt', 'pos/cv058_8025.txt', 'pos/cv059_28885.txt', 'pos/cv060_10844.txt', 'pos/cv061_8837.txt', 'pos/cv062_23115.txt', 'pos/cv063_28997.txt', 'pos/cv064_24576.txt', 'pos/cv065_15248.txt', 'pos/cv066_10821.txt', 'pos/cv067_19774.txt', 'pos/cv068_13400.txt', 'pos/cv069_10801.txt', 'pos/cv070_12289.txt', 'pos/cv071_12095.txt', 'pos/cv072_6169.txt', 'pos/cv073_21785.txt', 'pos/cv074_6875.txt', 'pos/cv075_6500.txt', 'pos/cv076_24945.txt', 'pos/cv077_22138.txt', 'pos/cv078_14730.txt', 'pos/cv079_11933.txt', 'pos/cv080_13465.txt', 'pos/cv081_16582.txt', 'pos/cv082_11080.txt', 'pos/cv083_24234.txt', 'pos/cv084_13566.txt', 'pos/cv085_1381.txt', 'pos/cv086_18371.txt', 'pos/cv087_1989.txt', 'pos/cv088_24113.txt', 'pos/cv089_11418.txt', 'pos/cv090_0042.txt', 'pos/cv091_7400.txt', 'pos/cv092_28017.txt', 'pos/cv093_13951.txt', 'pos/cv094_27889.txt', 'pos/cv095_28892.txt', 'pos/cv096_11474.txt', 'pos/cv097_24970.txt', 'pos/cv098_15435.txt', 'pos/cv099_10534.txt', 'pos/cv100_11528.txt', 'pos/cv101_10175.txt', 'pos/cv102_7846.txt', 'pos/cv103_11021.txt', 'pos/cv104_18134.txt', 'pos/cv105_17990.txt', 'pos/cv106_16807.txt', 'pos/cv107_24319.txt', 'pos/cv108_15571.txt', 'pos/cv109_21172.txt', 'pos/cv110_27788.txt', 'pos/cv111_11473.txt', 'pos/cv112_11193.txt', 'pos/cv113_23102.txt', 'pos/cv114_18398.txt', 'pos/cv115_25396.txt', 'pos/cv116_28942.txt', 'pos/cv117_24295.txt', 'pos/cv118_28980.txt', 'pos/cv119_9867.txt', 'pos/cv120_4111.txt', 'pos/cv121_17302.txt', 'pos/cv122_7392.txt', 'pos/cv123_11182.txt', 'pos/cv124_4122.txt', 'pos/cv125_9391.txt', 'pos/cv126_28971.txt', 'pos/cv127_14711.txt', 'pos/cv128_29627.txt', 'pos/cv129_16741.txt', 'pos/cv130_17083.txt', 'pos/cv131_10713.txt', 'pos/cv132_5618.txt', 'pos/cv133_16336.txt', 'pos/cv134_22246.txt', 'pos/cv135_11603.txt', 'pos/cv136_11505.txt', 'pos/cv137_15422.txt', 'pos/cv138_12721.txt', 'pos/cv139_12873.txt', 'pos/cv140_7479.txt', 'pos/cv141_15686.txt', 'pos/cv142_22516.txt', 'pos/cv143_19666.txt', 'pos/cv144_5007.txt', 'pos/cv145_11472.txt', 'pos/cv146_18458.txt', 'pos/cv147_21193.txt', 'pos/cv148_16345.txt', 'pos/cv149_15670.txt', 'pos/cv150_12916.txt', 'pos/cv151_15771.txt', 'pos/cv152_8736.txt', 'pos/cv153_10779.txt', 'pos/cv154_9328.txt', 'pos/cv155_7308.txt', 'pos/cv156_10481.txt', 'pos/cv157_29372.txt', 'pos/cv158_10390.txt', 'pos/cv159_29505.txt', 'pos/cv160_10362.txt', 'pos/cv161_11425.txt', 'pos/cv162_10424.txt', 'pos/cv163_10052.txt', 'pos/cv164_22447.txt', 'pos/cv165_22619.txt', 'pos/cv166_11052.txt', 'pos/cv167_16376.txt', 'pos/cv168_7050.txt', 'pos/cv169_23778.txt', 'pos/cv170_3006.txt', 'pos/cv171_13537.txt', 'pos/cv172_11131.txt', 'pos/cv173_4471.txt', 'pos/cv174_9659.txt', 'pos/cv175_6964.txt', 'pos/cv176_12857.txt', 'pos/cv177_10367.txt', 'pos/cv178_12972.txt', 'pos/cv179_9228.txt', 'pos/cv180_16113.txt', 'pos/cv181_14401.txt', 'pos/cv182_7281.txt', 'pos/cv183_18612.txt', 'pos/cv184_2673.txt', 'pos/cv185_28654.txt', 'pos/cv186_2269.txt', 'pos/cv187_12829.txt', 'pos/cv188_19226.txt', 'pos/cv189_22934.txt', 'pos/cv190_27052.txt', 'pos/cv191_29719.txt', 'pos/cv192_14395.txt', 'pos/cv193_5416.txt', 'pos/cv194_12079.txt', 'pos/cv195_14528.txt', 'pos/cv196_29027.txt', 'pos/cv197_29328.txt', 'pos/cv198_18180.txt', 'pos/cv199_9629.txt', 'pos/cv200_2915.txt', 'pos/cv201_6997.txt', 'pos/cv202_10654.txt', 'pos/cv203_17986.txt', 'pos/cv204_8451.txt', 'pos/cv205_9457.txt', 'pos/cv206_14293.txt', 'pos/cv207_29284.txt', 'pos/cv208_9020.txt', 'pos/cv209_29118.txt', 'pos/cv210_9312.txt', 'pos/cv211_9953.txt', 'pos/cv212_10027.txt', 'pos/cv213_18934.txt', 'pos/cv214_12294.txt', 'pos/cv215_22240.txt', 'pos/cv216_18738.txt', 'pos/cv217_28842.txt', 'pos/cv218_24352.txt', 'pos/cv219_18626.txt', 'pos/cv220_29059.txt', 'pos/cv221_2695.txt', 'pos/cv222_17395.txt', 'pos/cv223_29066.txt', 'pos/cv224_17661.txt', 'pos/cv225_29224.txt', 'pos/cv226_2618.txt', 'pos/cv227_24215.txt', 'pos/cv228_5806.txt', 'pos/cv229_13611.txt', 'pos/cv230_7428.txt', 'pos/cv231_10425.txt', 'pos/cv232_14991.txt', 'pos/cv233_15964.txt', 'pos/cv234_20643.txt', 'pos/cv235_10217.txt', 'pos/cv236_11565.txt', 'pos/cv237_19221.txt', 'pos/cv238_12931.txt', 'pos/cv239_3385.txt', 'pos/cv240_14336.txt', 'pos/cv241_23130.txt', 'pos/cv242_10638.txt', 'pos/cv243_20728.txt', 'pos/cv244_21649.txt', 'pos/cv245_8569.txt', 'pos/cv246_28807.txt', 'pos/cv247_13142.txt', 'pos/cv248_13987.txt', 'pos/cv249_11640.txt', 'pos/cv250_25616.txt', 'pos/cv251_22636.txt', 'pos/cv252_23779.txt', 'pos/cv253_10077.txt', 'pos/cv254_6027.txt', 'pos/cv255_13683.txt', 'pos/cv256_14740.txt', 'pos/cv257_10975.txt', 'pos/cv258_5792.txt', 'pos/cv259_10934.txt', 'pos/cv260_13959.txt', 'pos/cv261_10954.txt', 'pos/cv262_12649.txt', 'pos/cv263_19259.txt', 'pos/cv264_12801.txt', 'pos/cv265_10814.txt', 'pos/cv266_25779.txt', 'pos/cv267_14952.txt', 'pos/cv268_18834.txt', 'pos/cv269_21732.txt', 'pos/cv270_6079.txt', 'pos/cv271_13837.txt', 'pos/cv272_18974.txt', 'pos/cv273_29112.txt', 'pos/cv274_25253.txt', 'pos/cv275_28887.txt', 'pos/cv276_15684.txt', 'pos/cv277_19091.txt', 'pos/cv278_13041.txt', 'pos/cv279_18329.txt', 'pos/cv280_8267.txt', 'pos/cv281_23253.txt', 'pos/cv282_6653.txt', 'pos/cv283_11055.txt', 'pos/cv284_19119.txt', 'pos/cv285_16494.txt', 'pos/cv286_25050.txt', 'pos/cv287_15900.txt', 'pos/cv288_18791.txt', 'pos/cv289_6463.txt', 'pos/cv290_11084.txt', 'pos/cv291_26635.txt', 'pos/cv292_7282.txt', 'pos/cv293_29856.txt', 'pos/cv294_11684.txt', 'pos/cv295_15570.txt', 'pos/cv296_12251.txt', 'pos/cv297_10047.txt', 'pos/cv298_23111.txt', 'pos/cv299_16214.txt', 'pos/cv300_22284.txt', 'pos/cv301_12146.txt', 'pos/cv302_25649.txt', 'pos/cv303_27520.txt', 'pos/cv304_28706.txt', 'pos/cv305_9946.txt', 'pos/cv306_10364.txt', 'pos/cv307_25270.txt', 'pos/cv308_5016.txt', 'pos/cv309_22571.txt', 'pos/cv310_13091.txt', 'pos/cv311_16002.txt', 'pos/cv312_29377.txt', 'pos/cv313_18198.txt', 'pos/cv314_14422.txt', 'pos/cv315_11629.txt', 'pos/cv316_6370.txt', 'pos/cv317_24049.txt', 'pos/cv318_10493.txt', 'pos/cv319_14727.txt', 'pos/cv320_9530.txt', 'pos/cv321_12843.txt', 'pos/cv322_20318.txt', 'pos/cv323_29805.txt', 'pos/cv324_7082.txt', 'pos/cv325_16629.txt', 'pos/cv326_13295.txt', 'pos/cv327_20292.txt', 'pos/cv328_10373.txt', 'pos/cv329_29370.txt', 'pos/cv330_29809.txt', 'pos/cv331_8273.txt', 'pos/cv332_16307.txt', 'pos/cv333_8916.txt', 'pos/cv334_10001.txt', 'pos/cv335_14665.txt', 'pos/cv336_10143.txt', 'pos/cv337_29181.txt', 'pos/cv338_8821.txt', 'pos/cv339_21119.txt', 'pos/cv340_13287.txt', 'pos/cv341_24430.txt', 'pos/cv342_19456.txt', 'pos/cv343_10368.txt', 'pos/cv344_5312.txt', 'pos/cv345_9954.txt', 'pos/cv346_18168.txt', 'pos/cv347_13194.txt', 'pos/cv348_18176.txt', 'pos/cv349_13507.txt', 'pos/cv350_20670.txt', 'pos/cv351_15458.txt', 'pos/cv352_5524.txt', 'pos/cv353_18159.txt', 'pos/cv354_8132.txt', 'pos/cv355_16413.txt', 'pos/cv356_25163.txt', 'pos/cv357_13156.txt', 'pos/cv358_10691.txt', 'pos/cv359_6647.txt', 'pos/cv360_8398.txt', 'pos/cv361_28944.txt', 'pos/cv362_15341.txt', 'pos/cv363_29332.txt', 'pos/cv364_12901.txt', 'pos/cv365_11576.txt', 'pos/cv366_10221.txt', 'pos/cv367_22792.txt', 'pos/cv368_10466.txt', 'pos/cv369_12886.txt', 'pos/cv370_5221.txt', 'pos/cv371_7630.txt', 'pos/cv372_6552.txt', 'pos/cv373_20404.txt', 'pos/cv374_25436.txt', 'pos/cv375_9929.txt', 'pos/cv376_19435.txt', 'pos/cv377_7946.txt', 'pos/cv378_20629.txt', 'pos/cv379_21963.txt', 'pos/cv380_7574.txt', 'pos/cv381_20172.txt', 'pos/cv382_7897.txt', 'pos/cv383_13116.txt', 'pos/cv384_17140.txt', 'pos/cv385_29741.txt', 'pos/cv386_10080.txt', 'pos/cv387_11507.txt', 'pos/cv388_12009.txt', 'pos/cv389_9369.txt', 'pos/cv390_11345.txt', 'pos/cv391_10802.txt', 'pos/cv392_11458.txt', 'pos/cv393_29327.txt', 'pos/cv394_5137.txt', 'pos/cv395_10849.txt', 'pos/cv396_17989.txt', 'pos/cv397_29023.txt', 'pos/cv398_15537.txt', 'pos/cv399_2877.txt', 'pos/cv400_19220.txt', 'pos/cv401_12605.txt', 'pos/cv402_14425.txt', 'pos/cv403_6621.txt', 'pos/cv404_20315.txt', 'pos/cv405_20399.txt', 'pos/cv406_21020.txt', 'pos/cv407_22637.txt', 'pos/cv408_5297.txt', 'pos/cv409_29786.txt', 'pos/cv410_24266.txt', 'pos/cv411_15007.txt', 'pos/cv412_24095.txt', 'pos/cv413_7398.txt', 'pos/cv414_10518.txt', 'pos/cv415_22517.txt', 'pos/cv416_11136.txt', 'pos/cv417_13115.txt', 'pos/cv418_14774.txt', 'pos/cv419_13394.txt', 'pos/cv420_28795.txt', 'pos/cv421_9709.txt', 'pos/cv422_9381.txt', 'pos/cv423_11155.txt', 'pos/cv424_8831.txt', 'pos/cv425_8250.txt', 'pos/cv426_10421.txt', 'pos/cv427_10825.txt', 'pos/cv428_11347.txt', 'pos/cv429_7439.txt', 'pos/cv430_17351.txt', 'pos/cv431_7085.txt', 'pos/cv432_14224.txt', 'pos/cv433_10144.txt', 'pos/cv434_5793.txt', 'pos/cv435_23110.txt', 'pos/cv436_19179.txt', 'pos/cv437_22849.txt', 'pos/cv438_8043.txt', 'pos/cv439_15970.txt', 'pos/cv440_15243.txt', 'pos/cv441_13711.txt', 'pos/cv442_13846.txt', 'pos/cv443_21118.txt', 'pos/cv444_9974.txt', 'pos/cv445_25882.txt', 'pos/cv446_11353.txt', 'pos/cv447_27332.txt', 'pos/cv448_14695.txt', 'pos/cv449_8785.txt', 'pos/cv450_7890.txt', 'pos/cv451_10690.txt', 'pos/cv452_5088.txt', 'pos/cv453_10379.txt', 'pos/cv454_2053.txt', 'pos/cv455_29000.txt', 'pos/cv456_18985.txt', 'pos/cv457_18453.txt', 'pos/cv458_8604.txt', 'pos/cv459_20319.txt', 'pos/cv460_10842.txt', 'pos/cv461_19600.txt', 'pos/cv462_19350.txt', 'pos/cv463_10343.txt', 'pos/cv464_15650.txt', 'pos/cv465_22431.txt', 'pos/cv466_18722.txt', 'pos/cv467_25773.txt', 'pos/cv468_15228.txt', 'pos/cv469_20630.txt', 'pos/cv470_15952.txt', 'pos/cv471_16858.txt', 'pos/cv472_29280.txt', 'pos/cv473_7367.txt', 'pos/cv474_10209.txt', 'pos/cv475_21692.txt', 'pos/cv476_16856.txt', 'pos/cv477_22479.txt', 'pos/cv478_14309.txt', 'pos/cv479_5649.txt', 'pos/cv480_19817.txt', 'pos/cv481_7436.txt', 'pos/cv482_10580.txt', 'pos/cv483_16378.txt', 'pos/cv484_25054.txt', 'pos/cv485_26649.txt', 'pos/cv486_9799.txt', 'pos/cv487_10446.txt', 'pos/cv488_19856.txt', 'pos/cv489_17906.txt', 'pos/cv490_17872.txt', 'pos/cv491_12145.txt', 'pos/cv492_18271.txt', 'pos/cv493_12839.txt', 'pos/cv494_17389.txt', 'pos/cv495_14518.txt', 'pos/cv496_10530.txt', 'pos/cv497_26980.txt', 'pos/cv498_8832.txt', 'pos/cv499_10658.txt', 'pos/cv500_10251.txt', 'pos/cv501_11657.txt', 'pos/cv502_10406.txt', 'pos/cv503_10558.txt', 'pos/cv504_29243.txt', 'pos/cv505_12090.txt', 'pos/cv506_15956.txt', 'pos/cv507_9220.txt', 'pos/cv508_16006.txt', 'pos/cv509_15888.txt', 'pos/cv510_23360.txt', 'pos/cv511_10132.txt', 'pos/cv512_15965.txt', 'pos/cv513_6923.txt', 'pos/cv514_11187.txt', 'pos/cv515_17069.txt', 'pos/cv516_11172.txt', 'pos/cv517_19219.txt', 'pos/cv518_13331.txt', 'pos/cv519_14661.txt', 'pos/cv520_12295.txt', 'pos/cv521_15828.txt', 'pos/cv522_5583.txt', 'pos/cv523_16615.txt', 'pos/cv524_23627.txt', 'pos/cv525_16122.txt', 'pos/cv526_12083.txt', 'pos/cv527_10123.txt', 'pos/cv528_10822.txt', 'pos/cv529_10420.txt', 'pos/cv530_16212.txt', 'pos/cv531_26486.txt', 'pos/cv532_6522.txt', 'pos/cv533_9821.txt', 'pos/cv534_14083.txt', 'pos/cv535_19728.txt', 'pos/cv536_27134.txt', 'pos/cv537_12370.txt', 'pos/cv538_28667.txt', 'pos/cv539_20347.txt', 'pos/cv540_3421.txt', 'pos/cv541_28835.txt', 'pos/cv542_18980.txt', 'pos/cv543_5045.txt', 'pos/cv544_5108.txt', 'pos/cv545_12014.txt', 'pos/cv546_11767.txt', 'pos/cv547_16324.txt', 'pos/cv548_17731.txt', 'pos/cv549_21443.txt', 'pos/cv550_22211.txt', 'pos/cv551_10565.txt', 'pos/cv552_10016.txt', 'pos/cv553_26915.txt', 'pos/cv554_13151.txt', 'pos/cv555_23922.txt', 'pos/cv556_14808.txt', 'pos/cv557_11449.txt', 'pos/cv558_29507.txt', 'pos/cv559_0050.txt', 'pos/cv560_17175.txt', 'pos/cv561_9201.txt', 'pos/cv562_10359.txt', 'pos/cv563_17257.txt', 'pos/cv564_11110.txt', 'pos/cv565_29572.txt', 'pos/cv566_8581.txt', 'pos/cv567_29611.txt', 'pos/cv568_15638.txt', 'pos/cv569_26381.txt', 'pos/cv570_29082.txt', 'pos/cv571_29366.txt', 'pos/cv572_18657.txt', 'pos/cv573_29525.txt', 'pos/cv574_22156.txt', 'pos/cv575_21150.txt', 'pos/cv576_14094.txt', 'pos/cv577_28549.txt', 'pos/cv578_15094.txt', 'pos/cv579_11605.txt', 'pos/cv580_14064.txt', 'pos/cv581_19381.txt', 'pos/cv582_6559.txt', 'pos/cv583_29692.txt', 'pos/cv584_29722.txt', 'pos/cv585_22496.txt', 'pos/cv586_7543.txt', 'pos/cv587_19162.txt', 'pos/cv588_13008.txt', 'pos/cv589_12064.txt', 'pos/cv590_19290.txt', 'pos/cv591_23640.txt', 'pos/cv592_22315.txt', 'pos/cv593_10987.txt', 'pos/cv594_11039.txt', 'pos/cv595_25335.txt', 'pos/cv596_28311.txt', 'pos/cv597_26360.txt', 'pos/cv598_16452.txt', 'pos/cv599_20988.txt', 'pos/cv600_23878.txt', 'pos/cv601_23453.txt', 'pos/cv602_8300.txt', 'pos/cv603_17694.txt', 'pos/cv604_2230.txt', 'pos/cv605_11800.txt', 'pos/cv606_15985.txt', 'pos/cv607_7717.txt', 'pos/cv608_23231.txt', 'pos/cv609_23877.txt', 'pos/cv610_2287.txt', 'pos/cv611_21120.txt', 'pos/cv612_5461.txt', 'pos/cv613_21796.txt', 'pos/cv614_10626.txt', 'pos/cv615_14182.txt', 'pos/cv616_29319.txt', 'pos/cv617_9322.txt', 'pos/cv618_8974.txt', 'pos/cv619_12462.txt', 'pos/cv620_24265.txt', 'pos/cv621_14368.txt', 'pos/cv622_8147.txt', 'pos/cv623_15356.txt', 'pos/cv624_10744.txt', 'pos/cv625_12440.txt', 'pos/cv626_7410.txt', 'pos/cv627_11620.txt', 'pos/cv628_19325.txt', 'pos/cv629_14909.txt', 'pos/cv630_10057.txt', 'pos/cv631_4967.txt', 'pos/cv632_9610.txt', 'pos/cv633_29837.txt', 'pos/cv634_11101.txt', 'pos/cv635_10022.txt', 'pos/cv636_15279.txt', 'pos/cv637_1250.txt', 'pos/cv638_2953.txt', 'pos/cv639_10308.txt', 'pos/cv640_5378.txt', 'pos/cv641_12349.txt', 'pos/cv642_29867.txt', 'pos/cv643_29349.txt', 'pos/cv644_17154.txt', 'pos/cv645_15668.txt', 'pos/cv646_15065.txt', 'pos/cv647_13691.txt', 'pos/cv648_15792.txt', 'pos/cv649_12735.txt', 'pos/cv650_14340.txt', 'pos/cv651_10492.txt', 'pos/cv652_13972.txt', 'pos/cv653_19583.txt', 'pos/cv654_18246.txt', 'pos/cv655_11154.txt', 'pos/cv656_24201.txt', 'pos/cv657_24513.txt', 'pos/cv658_10532.txt', 'pos/cv659_19944.txt', 'pos/cv660_21893.txt', 'pos/cv661_2450.txt', 'pos/cv662_13320.txt', 'pos/cv663_13019.txt', 'pos/cv664_4389.txt', 'pos/cv665_29538.txt', 'pos/cv666_18963.txt', 'pos/cv667_18467.txt', 'pos/cv668_17604.txt', 'pos/cv669_22995.txt', 'pos/cv670_25826.txt', 'pos/cv671_5054.txt', 'pos/cv672_28083.txt', 'pos/cv673_24714.txt', 'pos/cv674_10732.txt', 'pos/cv675_21588.txt', 'pos/cv676_21090.txt', 'pos/cv677_17715.txt', 'pos/cv678_13419.txt', 'pos/cv679_28559.txt', 'pos/cv680_10160.txt', 'pos/cv681_9692.txt', 'pos/cv682_16139.txt', 'pos/cv683_12167.txt', 'pos/cv684_11798.txt', 'pos/cv685_5947.txt', 'pos/cv686_13900.txt', 'pos/cv687_21100.txt', 'pos/cv688_7368.txt', 'pos/cv689_12587.txt', 'pos/cv690_5619.txt', 'pos/cv691_5043.txt', 'pos/cv692_15451.txt', 'pos/cv693_18063.txt', 'pos/cv694_4876.txt', 'pos/cv695_21108.txt', 'pos/cv696_29740.txt', 'pos/cv697_11162.txt', 'pos/cv698_15253.txt', 'pos/cv699_7223.txt', 'pos/cv700_21947.txt', 'pos/cv701_14252.txt', 'pos/cv702_11500.txt', 'pos/cv703_16143.txt', 'pos/cv704_15969.txt', 'pos/cv705_11059.txt', 'pos/cv706_24716.txt', 'pos/cv707_10678.txt', 'pos/cv708_28729.txt', 'pos/cv709_10529.txt', 'pos/cv710_22577.txt', 'pos/cv711_11665.txt', 'pos/cv712_22920.txt', 'pos/cv713_29155.txt', 'pos/cv714_18502.txt', 'pos/cv715_18179.txt', 'pos/cv716_10514.txt', 'pos/cv717_15953.txt', 'pos/cv718_11434.txt', 'pos/cv719_5713.txt', 'pos/cv720_5389.txt', 'pos/cv721_29121.txt', 'pos/cv722_7110.txt', 'pos/cv723_8648.txt', 'pos/cv724_13681.txt', 'pos/cv725_10103.txt', 'pos/cv726_4719.txt', 'pos/cv727_4978.txt', 'pos/cv728_16133.txt', 'pos/cv729_10154.txt', 'pos/cv730_10279.txt', 'pos/cv731_4136.txt', 'pos/cv732_12245.txt', 'pos/cv733_9839.txt', 'pos/cv734_21568.txt', 'pos/cv735_18801.txt', 'pos/cv736_23670.txt', 'pos/cv737_28907.txt', 'pos/cv738_10116.txt', 'pos/cv739_11209.txt', 'pos/cv740_12445.txt', 'pos/cv741_11890.txt', 'pos/cv742_7751.txt', 'pos/cv743_15449.txt', 'pos/cv744_10038.txt', 'pos/cv745_12773.txt', 'pos/cv746_10147.txt', 'pos/cv747_16556.txt', 'pos/cv748_12786.txt', 'pos/cv749_17765.txt', 'pos/cv750_10180.txt', 'pos/cv751_15719.txt', 'pos/cv752_24155.txt', 'pos/cv753_10875.txt', 'pos/cv754_7216.txt', 'pos/cv755_23616.txt', 'pos/cv756_22540.txt', 'pos/cv757_10189.txt', 'pos/cv758_9671.txt', 'pos/cv759_13522.txt', 'pos/cv760_8597.txt', 'pos/cv761_12620.txt', 'pos/cv762_13927.txt', 'pos/cv763_14729.txt', 'pos/cv764_11739.txt', 'pos/cv765_19037.txt', 'pos/cv766_7540.txt', 'pos/cv767_14062.txt', 'pos/cv768_11751.txt', 'pos/cv769_8123.txt', 'pos/cv770_10451.txt', 'pos/cv771_28665.txt', 'pos/cv772_12119.txt', 'pos/cv773_18817.txt', 'pos/cv774_13845.txt', 'pos/cv775_16237.txt', 'pos/cv776_20529.txt', 'pos/cv777_10094.txt', 'pos/cv778_17330.txt', 'pos/cv779_17881.txt', 'pos/cv780_7984.txt', 'pos/cv781_5262.txt', 'pos/cv782_19526.txt', 'pos/cv783_13227.txt', 'pos/cv784_14394.txt', 'pos/cv785_22600.txt', 'pos/cv786_22497.txt', 'pos/cv787_13743.txt', 'pos/cv788_25272.txt', 'pos/cv789_12136.txt', 'pos/cv790_14600.txt', 'pos/cv791_16302.txt', 'pos/cv792_3832.txt', 'pos/cv793_13650.txt', 'pos/cv794_15868.txt', 'pos/cv795_10122.txt', 'pos/cv796_15782.txt', 'pos/cv797_6957.txt', 'pos/cv798_23531.txt', 'pos/cv799_18543.txt', 'pos/cv800_12368.txt', 'pos/cv801_25228.txt', 'pos/cv802_28664.txt', 'pos/cv803_8207.txt', 'pos/cv804_10862.txt', 'pos/cv805_19601.txt', 'pos/cv806_8842.txt', 'pos/cv807_21740.txt', 'pos/cv808_12635.txt', 'pos/cv809_5009.txt', 'pos/cv810_12458.txt', 'pos/cv811_21386.txt', 'pos/cv812_17924.txt', 'pos/cv813_6534.txt', 'pos/cv814_18975.txt', 'pos/cv815_22456.txt', 'pos/cv816_13655.txt', 'pos/cv817_4041.txt', 'pos/cv818_10211.txt', 'pos/cv819_9364.txt', 'pos/cv820_22892.txt', 'pos/cv821_29364.txt', 'pos/cv822_20049.txt', 'pos/cv823_15569.txt', 'pos/cv824_8838.txt', 'pos/cv825_5063.txt', 'pos/cv826_11834.txt', 'pos/cv827_18331.txt', 'pos/cv828_19831.txt', 'pos/cv829_20289.txt', 'pos/cv830_6014.txt', 'pos/cv831_14689.txt', 'pos/cv832_23275.txt', 'pos/cv833_11053.txt', 'pos/cv834_22195.txt', 'pos/cv835_19159.txt', 'pos/cv836_12968.txt', 'pos/cv837_27325.txt', 'pos/cv838_24728.txt', 'pos/cv839_21467.txt', 'pos/cv840_16321.txt', 'pos/cv841_3967.txt', 'pos/cv842_5866.txt', 'pos/cv843_15544.txt', 'pos/cv844_12690.txt', 'pos/cv845_14290.txt', 'pos/cv846_29497.txt', 'pos/cv847_1941.txt', 'pos/cv848_10036.txt', 'pos/cv849_15729.txt', 'pos/cv850_16466.txt', 'pos/cv851_20469.txt', 'pos/cv852_27523.txt', 'pos/cv853_29233.txt', 'pos/cv854_17740.txt', 'pos/cv855_20661.txt', 'pos/cv856_29013.txt', 'pos/cv857_15958.txt', 'pos/cv858_18819.txt', 'pos/cv859_14107.txt', 'pos/cv860_13853.txt', 'pos/cv861_1198.txt', 'pos/cv862_14324.txt', 'pos/cv863_7424.txt', 'pos/cv864_3416.txt', 'pos/cv865_2895.txt', 'pos/cv866_29691.txt', 'pos/cv867_16661.txt', 'pos/cv868_11948.txt', 'pos/cv869_23611.txt', 'pos/cv870_16348.txt', 'pos/cv871_24888.txt', 'pos/cv872_12591.txt', 'pos/cv873_18636.txt', 'pos/cv874_11236.txt', 'pos/cv875_5754.txt', 'pos/cv876_9390.txt', 'pos/cv877_29274.txt', 'pos/cv878_15694.txt', 'pos/cv879_14903.txt', 'pos/cv880_29800.txt', 'pos/cv881_13254.txt', 'pos/cv882_10026.txt', 'pos/cv883_27751.txt', 'pos/cv884_13632.txt', 'pos/cv885_12318.txt', 'pos/cv886_18177.txt', 'pos/cv887_5126.txt', 'pos/cv888_24435.txt', 'pos/cv889_21430.txt', 'pos/cv890_3977.txt', 'pos/cv891_6385.txt', 'pos/cv892_17576.txt', 'pos/cv893_26269.txt', 'pos/cv894_2068.txt', 'pos/cv895_21022.txt', 'pos/cv896_16071.txt', 'pos/cv897_10837.txt', 'pos/cv898_14187.txt', 'pos/cv899_16014.txt', 'pos/cv900_10331.txt', 'pos/cv901_11017.txt', 'pos/cv902_12256.txt', 'pos/cv903_17822.txt', 'pos/cv904_24353.txt', 'pos/cv905_29114.txt', 'pos/cv906_11491.txt', 'pos/cv907_3541.txt', 'pos/cv908_16009.txt', 'pos/cv909_9960.txt', 'pos/cv910_20488.txt', 'pos/cv911_20260.txt', 'pos/cv912_5674.txt', 'pos/cv913_29252.txt', 'pos/cv914_28742.txt', 'pos/cv915_8841.txt', 'pos/cv916_15467.txt', 'pos/cv917_29715.txt', 'pos/cv918_2693.txt', 'pos/cv919_16380.txt', 'pos/cv920_29622.txt', 'pos/cv921_12747.txt', 'pos/cv922_10073.txt', 'pos/cv923_11051.txt', 'pos/cv924_29540.txt', 'pos/cv925_8969.txt', 'pos/cv926_17059.txt', 'pos/cv927_10681.txt', 'pos/cv928_9168.txt', 'pos/cv929_16908.txt', 'pos/cv930_13475.txt', 'pos/cv931_17563.txt', 'pos/cv932_13401.txt', 'pos/cv933_23776.txt', 'pos/cv934_19027.txt', 'pos/cv935_23841.txt', 'pos/cv936_15954.txt', 'pos/cv937_9811.txt', 'pos/cv938_10220.txt', 'pos/cv939_10583.txt', 'pos/cv940_17705.txt', 'pos/cv941_10246.txt', 'pos/cv942_17082.txt', 'pos/cv943_22488.txt', 'pos/cv944_13521.txt', 'pos/cv945_12160.txt', 'pos/cv946_18658.txt', 'pos/cv947_10601.txt', 'pos/cv948_24606.txt', 'pos/cv949_20112.txt', 'pos/cv950_12350.txt', 'pos/cv951_10926.txt', 'pos/cv952_25240.txt', 'pos/cv953_6836.txt', 'pos/cv954_18628.txt', 'pos/cv955_25001.txt', 'pos/cv956_11609.txt', 'pos/cv957_8737.txt', 'pos/cv958_12162.txt', 'pos/cv959_14611.txt', 'pos/cv960_29007.txt', 'pos/cv961_5682.txt', 'pos/cv962_9803.txt', 'pos/cv963_6895.txt', 'pos/cv964_6021.txt', 'pos/cv965_26071.txt', 'pos/cv966_28832.txt', 'pos/cv967_5788.txt', 'pos/cv968_24218.txt', 'pos/cv969_13250.txt', 'pos/cv970_18450.txt', 'pos/cv971_10874.txt', 'pos/cv972_26417.txt', 'pos/cv973_10066.txt', 'pos/cv974_22941.txt', 'pos/cv975_10981.txt', 'pos/cv976_10267.txt', 'pos/cv977_4938.txt', 'pos/cv978_20929.txt', 'pos/cv979_18921.txt', 'pos/cv980_10953.txt', 'pos/cv981_14989.txt', 'pos/cv982_21103.txt', 'pos/cv983_22928.txt', 'pos/cv984_12767.txt', 'pos/cv985_6359.txt', 'pos/cv986_13527.txt', 'pos/cv987_6965.txt', 'pos/cv988_18740.txt', 'pos/cv989_15824.txt', 'pos/cv990_11591.txt', 'pos/cv991_18645.txt', 'pos/cv992_11962.txt', 'pos/cv993_29737.txt', 'pos/cv994_12270.txt', 'pos/cv995_21821.txt', 'pos/cv996_11592.txt', 'pos/cv997_5046.txt', 'pos/cv998_14111.txt', 'pos/cv999_13106.txt']
At threshold = 0; 61.00% correct
At threshold = 0; 0 reviews were too ambiguous.
At threshold = 0.025; 63.33% correct
At threshold = 0.025; 10 reviews were too ambiguous.
At threshold = 0.05; 63.38% correct
At threshold = 0.05; 29 reviews were too ambiguous.
At threshold = 0.1; 63.04% correct
At threshold = 0.1; 54 reviews were too ambiguous.
At threshold = 0.125; 72.22% correct
At threshold = 0.125; 64 reviews were too ambiguous.
At threshold = 0.15; 77.78% correct
At threshold = 0.15; 73 reviews were too ambiguous.
At threshold = 0.2; 86.67% correct
At threshold = 0.2; 85 reviews were too ambiguous.
The Bing Liu Lexicon#
Unlike the VADER lexicon which contains word samples with specific sentiment scores, the Bing-Liu lexicon consist of two separate word samples without any specific score. Instead, there is a a list of words which express positive opinion and a separate list of words which express negative opinion. Furthermore, The Bing Liu lexicon also contain misspelled words to make it more suitable for application on texts extracted from online discussion forums, social media, and other such sources including Amazon customer reviews data.
This lexicon is also available from NLTK (called as “opinion_lexicon”):
from nltk.corpus import opinion_lexicon
nltk.download('opinion_lexicon')
An approach to use the Bing Liu lexicon on a reviewText can be described as follows:
First, create a Bing Liu word dictionary with “word” as the key and a specified sentiment score as the value {“word”:score} where
“word” is each word in the Bing Liu Lexicon
score is +1 if the “word” is from the positive list and -1 if the “word” is from the negative list.
Then, for each review entry, -Word-tokenize the reviewText -For each word in reviewText, get its sentiment score from the Bing Liu word dictionary -Aggregate the total sentiment score for the reviewText and compute average score.
Bing Liu application on Amazon product review#
In this example, we will apply Bing Liu application on Amazon Product Review text. The source for the text data is https://nijianmo.github.io/amazon/index.html and we use the 2018 Amazon Review data. The specific Product Review text we will analysis is the product review for Magazine Subscriptions (Magazine_Subscriptions_5.json.gz)
See also (the main source).
The Amazon Product Review data for magazine subscription contains the following fields:
Overall: This is the final rating provided by the reviewer. Ranges from 1 (lowest) to 5 (highest).
Verified: This indicates whether the product purchase has been verified by Amazon.
ReviewerID: A unique identifier allocated by Amazon to each reviewer.
asin: A unique product code that Amazon uses to identify the product.
reviewText: The actual text in the review provided by the user.
Summary: This is the headline or summary of the review that the user provided
The Amazon Product Review data is in a JSON data exchange format. On a glance, a JSON file looks like a Python dictionary. However, it must be noted that a JSON file is a normal string/text file. In contrast, a Python dictionary is a Python object residing in the memory. In other words, a JSON file is basically a normal text file in which its rows looks like a Python dictionary which may represent each row in a DataFrame.

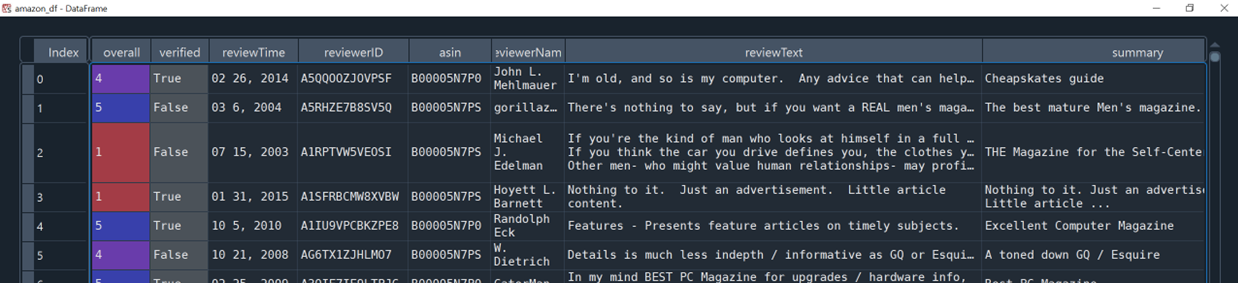
We can load a JSON file onto a DataFrame using Pandas’ read_json. Notice that in this example, our JSON file is compressed as gzip file. Pandas can handle this type of compressed file directly.
amazon_df = pd.read_json('Magazine_Subscriptions_5.json.gz', lines=True)
amazon_df.sample(5)
As described earlier, we first import the Bing Liu lexicon and create a dictionary object bingliuworddict and populate it with the words from Bing Liu Lexicon’s positive and negative list with +1 and -1 as the value.
# Create a dictionary which we can use for scoring our review text
pos_score = 1
neg_score = -1
bingliuworddict = {}
# Adding the positive words to the dictionary
for word in opinion_lexicon.positive():
bingliuworddict[word] = pos_score
# Adding the negative words to the dictionary
for word in opinion_lexicon.negative():
bingliuworddict[word] = neg_score
Then, the sentiment analysis scoring is done in a custom function bing_liu_score(text) which takes an input text, word tokenises it, and then compute the average sentiment score.
def bing_liu_score(text):
"""
A function to compute the sentiment score of the input "text" based
on Bing Liu Lexicons
"""
#word as the token
from nltk.tokenize import word_tokenize
sentiment_score = 0
try:
bag_of_words = word_tokenize(text.lower())
except:
print("skipping review; cant create bag of words")
else:
for word in bag_of_words:
if word in bingliuworddict:
sentiment_score += bingliuworddict[word]
return sentiment_score / len(bag_of_words)
To compute the Bing Liu sentiment score for all of the review text in the Amazon data, we use Pandas’ .apply() method to apply bing_liu_score function on each row on the column reviewText:
# Apply the bing_liu_score function on each row of the review text column ('text')
amazon_df['Bing_Liu_Score'] = amazon_df['reviewText'].apply(bing_liu_score)
#see a random sample of 2 reviewText and their sentiment scores
sample10_df = amazon_df[['asin','reviewText','Bing_Liu_Score']].sample(10)
#comparing Bing_Liu_Score to the Overall rating (1-5 stars)
amazon_df.groupby('overall').agg({'Bing_Liu_Score':'mean'})
On the last line above, we compute the average Bing Liu Score of each classification under the overall column. The classifications in the overall column are associated with Amazon’s *, **, ***, ****, and ***** ratings assigned by each human reviewer. From the results, we can infer, for example the following classfication:
* (one star): \(\textrm{Bing Liu score} < 0.011\)
** (two stars): \(0.011 <= \textrm{Bing Liu score} < 0.018\)
*** (three stars): \(0.018 <= \textrm{Bing Liu score} < 0.037\)
**** (four stars): \(0.037 <= \textrm{Bing Liu score} < 0.109\)
***** (five stars): \(\textrm{Bing Liu score} >= 0.109\)
#%% Using Bing Liu Lexicon on Amazon Magazine Review data
import nltk
import pandas as pd
amazon_df = pd.read_json('Magazine_Subscriptions_5.json.gz', lines=True)
amazon_df.sample(5)
#importing the Bing Liu lexicon
from nltk.corpus import opinion_lexicon
#if necessary, download first
nltk.download('opinion_lexicon')
#summary measures of the opinion_lexicon
print('Total number of words in opinion lexicon', len(opinion_lexicon.words()))
print('Examples of positive words in opinion lexicon',
opinion_lexicon.positive()[:5])
print('Examples of negative words in opinion lexicon',
opinion_lexicon.negative()[:5])
# Create a dictionary which we can use for scoring our review text
pos_score = 1
neg_score = -1
bingliuworddict = {}
# Adding the positive words to the dictionary
for word in opinion_lexicon.positive():
bingliuworddict[word] = pos_score
# Adding the negative words to the dictionary
for word in opinion_lexicon.negative():
bingliuworddict[word] = neg_score
# A function to compute the sentiment score based on Bing Liu Lexicons
def bing_liu_score(text):
"""
A function to compute the sentiment score of the input "text" based
on Bing Liu Lexicons
"""
#word as the token
from nltk.tokenize import word_tokenize
sentiment_score = 0
try:
bag_of_words = word_tokenize(text.lower())
except:
print("skipping review; cant create bag of words")
else:
for word in bag_of_words:
if word in bingliuworddict:
sentiment_score += bingliuworddict[word]
return sentiment_score / len(bag_of_words)
# Apply the bing_liu_score function on each row of the review text column ('text')
amazon_df['Bing_Liu_Score'] = amazon_df['reviewText'].apply(bing_liu_score)
#see a random sample of 2 reviewText and their sentiment scores
sample10_df = amazon_df[['asin','reviewText','Bing_Liu_Score']].sample(10)
#comparing Bing_Liu_Score to the Overall rating (1-5 stars)
amazon_df.groupby('overall').agg({'Bing_Liu_Score':'mean'})
[nltk_data] Downloading package opinion_lexicon to
[nltk_data] C:\Users\apalangkaraya\AppData\Roaming\nltk_data...
[nltk_data] Package opinion_lexicon is already up-to-date!
Total number of words in opinion lexicon 6789
Examples of positive words in opinion lexicon ['a+', 'abound', 'abounds', 'abundance', 'abundant']
Examples of negative words in opinion lexicon ['2-faced', '2-faces', 'abnormal', 'abolish', 'abominable']
skipping review; cant create bag of words
| Bing_Liu_Score | |
|---|---|
| overall | |
| 1 | 0.011047 |
| 2 | 0.018279 |
| 3 | 0.036957 |
| 4 | 0.108515 |
| 5 | 0.175080 |
Doing Sentiment Analysis with Machine Learning#
Limitations of the Lexicon approach#
From our previous discussions and examples, we can summarise a few limitations of using the Lexicon approach to do sentiment analysis.
THe size of the lexicon. If a word does not exist in the chosen lexicon, then the sentiment score does nont capture all the words in the text.
The chosen lexicon may not be the gold standard, nor the sentiment score/polarity provided by the lexicon’s author(s). A particular lexicon may not be suitable for the intended purpose.
Bing Liu lexicon is more suitable for online usage of language
VADER lexicon would be better suited for Twitter’s tweets since it includes support for popular acronyms (e.g., LOL) and emojis.
Lexicons overlook negation because they only match words and not phrases. Sentence containing the phrase “not bad” would be rated negative instead of neutral.
Alternative approaches? Supervised machine learning (but, we need labelled sentiment data).
Applying Support Vector Machine (SVM) for sentiment analysis#
The Support Vector Machine (SVM) is a Machine Learning algorithm with a basic idea of, given the observed data represented by the “dots” and “crosses” as illustrated in the following diagram (see Mark E. Fenner’s Machine Learning with Python for Everyone), how to find the best support vectors to separate the two classes implied by the observed data.
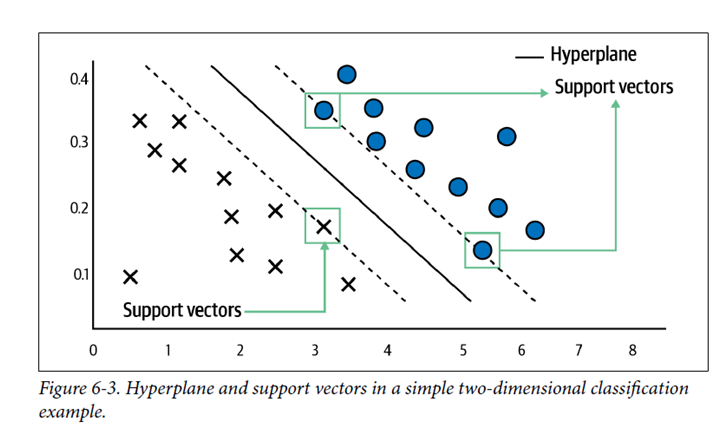
In the sentiment analysis, we can imagine that the “dots” represent the negative valued text and the “crosses” represent the positive valued text such that the sentiment analysis problem is translated into an SVM estimation problem of finding the the two support vectors represented by the dashed lines.
While a full discussion of the algorithm of the SVM model and its estimation are beyond this course, we can still discuss how we can use the sklearn module to implement the model. In essence, SVM algorithm is preferred (relative to a linear regression or non-linear logistic or other basic ML models) when working with text data because it is more suited to work with sparse data and when the input features are purely numeric (as in the case of TFIDF word vectors) instead of categorical. There are available SVM estimation functions in sklear depending on the actual implementation:
sklearn.svm.SVC(can be specified to produce LinearSVC model, but slower)sklearn.svm.LinearSVC(This is more specific than the other two, but much faster)sklearn.linear_model.SGDClassifier(can be specified to produce LinearSVC model, but slower)
In the following example, which consists of six steps, we will implement the SVM model to redo the Amazon magazine subscription review sentiment analysis:
Step 0: Load the Amazaon Magazine Subscription Review data to DataFrame and create target variable
Step 1: Pre-process the review text
Step 2: Split the data into train and test sample
Step 3: Vectorizing the reviewText using TF-IDF vector representations
Step 4: Train the SVM Classifier
Step 5: Evaluating the predictive performance of the SVM Classifier
In Step 0, we load the Magazine Subscription product review data into DataFrame in a similar way shown in the previous example by using Pandas’ .read_json() method. The most important part in this first step is the creation of the target variable which we store in sentiment column in the DataFrame (amazon_df). To simplify the classification problem, in this example we only consider a binary classification for the sentiment column as the target variable:
\('sentiment' = 1 \textrm{ if 'overall'} > 3\)
\('sentiment' = 0 \textrm{ if 'overall'} <=3\) Thus, we defined a ‘positive’ review as review with 4 and 5 stars overall rating.
# Assigning a new [1,0] target class label based on the product rating
# sentiment = 0 (negative); sentiment = 1 (positive)
amazon_df['sentiment'] = 0
amazon_df.loc[amazon_df['overall'] > 3, 'sentiment'] = 1
amazon_df.loc[amazon_df['overall'] < 3, 'sentiment'] = 0
To make the classification problem even simpler, we also drop any case in which overall=3 since it is probably a neutral review. Furthermore, we also drop non-verified review since we want to be certain that our target variable to have as little noise as possible which may come from inconsistent ‘overall’ rating and the actual text of the review.
# Drop rows if overall rating is 3
amazon_df = amazon_df[amazon_df.overall!=3]
# Use only verified reviews
amazon_df = amazon_df[amazon_df.verified==True]
This step leaves up with a sample size of \(n = 1,571\) review text with a sentiment classification of positive reviews (1,454) and negative reviews (117). Obviously, this sample distribution is skewed toward positive reviews. This might have some undesirable implications on our SVM model, so we will need to do some stratified random sampling when setting up the training and test sample as discussed later.
#%% Amazon Review: supervised learning approach for sentiment analysis
import pandas as pd
# STEP0: Load the data to DataFrame
amazon_df = pd.read_json('Magazine_Subscriptions_5.json.gz', lines=True)
# Assigning a new [1,0] target class label based on the product rating
# sentiment = 0 (negative); sentiment = 1 (positive)
amazon_df['sentiment'] = 0
amazon_df.loc[amazon_df['overall'] > 3, 'sentiment'] = 1
amazon_df.loc[amazon_df['overall'] < 3, 'sentiment'] = 0
# Drop rows if overall rating is 3
amazon_df = amazon_df[amazon_df.overall!=3]
# Use only verified reviews
amazon_df = amazon_df[amazon_df.verified==True]
# Removing unnecessary columns to keep a simple DataFrame
amazon_df.drop(columns=['reviewTime', 'unixReviewTime', 'overall',
'reviewerID', 'summary', 'vote', 'image',
'style', 'reviewerName' ], inplace=True)
amazon_df.sample(3)
#tabulate the sentiment value (data is skewed, most review is positive)
amazon_df['sentiment'].value_counts()
sentiment
1 1454
0 117
Name: count, dtype: int64
In Step 1, we proceed to pre-process the review text in the usual ways:
Clean the text from non-alphanumeric characters
# First clean the text from an any special characters, HTML tags, and URLs:
amazon_df['text_orig'] = amazon_df['reviewText'].copy()
amazon_df['reviewText'] = amazon_df['reviewText'].apply(clean)
Normalise to lower case and Lemmatise with parts-of-speech tagging
# Preprocessed
amazon_df['reviewText'] = amazon_df['reviewText'].apply(prep)
Each of the above pre-processing steps is done by a custom function namely: clean() and prep (which calls a custom function get_wordnet_pos and a NLTK’s WordNetLemmatizer).
Lastly, we drop if drop the cleaned reviewText is empty.
amazon_df = amazon_df[amazon_df['reviewText'].str.len()!=0]
# STEP 1: Now prepare the review text data
def clean(text):
"""
Text cleaning function taken from Blueprints for Text Analytics
The function uses Regular Expression fro the clearning
"""
import html
import re
# convert html escapes like & to characters.
try:
text = html.unescape(text)
except:
print('error in handling html escape')
else:
try:
# tags like <tab>
text = re.sub(r'<[^<>]*>', ' ', text)
except:
print('error in regular expression')
return text.strip()
else:
# markdown URLs like [Some text](https://....)
text = re.sub(r'\[([^\[\]]*)\]\([^\(\)]*\)', r'\1', text)
# text or code in brackets like [0]
text = re.sub(r'\[[^\[\]]*\]', ' ', text)
# standalone sequences of specials, matches &# but not #cool
text = re.sub(r'(?:^|\s)[&#<>{}\[\]+|\\:-]{1,}(?:\s|$)', ' ', text)
# standalone sequences of hyphens like --- or ==
text = re.sub(r'(?:^|\s)[\-=\+]{2,}(?:\s|$)', ' ', text)
# sequences of white spaces
text = re.sub(r'\s+', ' ', text)
return text.strip()
# First clean the text from an any special characters, HTML tags, and URLs:
amazon_df['text_orig'] = amazon_df['reviewText'].copy()
amazon_df['reviewText'] = amazon_df['reviewText'].apply(clean)
# Second preprocess the text (lower case, no punctuations, etc)
def get_wordnet_pos(word):
""" Get Part-of-speech (POS) tag of input word, and return the first POS
tag character (which is the character that lemmatize() accepts as input)
"""
from nltk import pos_tag
from nltk.corpus import wordnet
tag_firstchar = pos_tag([word])[0][1][0].upper()
tag_dict = {'J': wordnet.ADJ,
'N': wordnet.NOUN,
'V': wordnet.VERB,
'R': wordnet.ADV}
return tag_dict.get(tag_firstchar, wordnet.NOUN) # Note that the default value to return is "N" (NOUN)
#preprocess function
def prep(docs, filtpunc=True):
"""
Input: English sentences
Output: preprocessed list of sentences
Preprocessing:
1. filtered punctuations (if punct==True)
2. lemmatized (with POS tag) and converted to lowercase.
"""
from nltk import word_tokenize, sent_tokenize
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
docs_p = []
if docs == None:
return docs_p
else:
try:
docs = sent_tokenize(docs, language='english')
except:
print('No need sentence tokenizing')
for doc in docs:
#word tokenize
doc = word_tokenize(doc, language="english")
#convert lowercase then remove punctuations
if filtpunc:
doc =[word.lower() for word in doc if word.isalpha()]
else:
doc =[word.lower() for word in doc]
#lemmatize
doc = [lemmatizer.lemmatize(
word, pos=get_wordnet_pos(word)) for word in doc]
#join the words into the original doc format
docs_p.append(' '.join(doc))
return ''.join(str(x) for x in docs_p)
# Preprocessed
amazon_df['reviewText'] = amazon_df['reviewText'].apply(prep)
#doc = "I'm old, and so is my computer. Any advice that can help me maximize my computer perfomance is very welcome. MaximumPC has some good tips on computer parts, vendors, and usefull tests"
#print(prep(doc))
#drop if cleaned reviewText is empty
amazon_df = amazon_df[amazon_df['reviewText'].str.len()!=0]
error in handling html escape
In Step 2, we set up the training and test sample. Since the sample is skewed (most of sentiment is positive), we use sentiment classfication to stratify the random sampling to ensure that the resulting sample split has similar proportion to before the split.
Note
In more advanced ML techniques, we may want to do random re-sampling to create a more balanced sample to improve the predictive performance of the SVM model.
To split the sample, we call sklearn.model_selection’s train_test_split:
x_train, x_test, y_train, y_test = train_test_split(amazon_df['reviewText'],
amazon_df['sentiment'],
test_size=0.2,
random_state=42,
stratify=amazon_df['sentiment'])
By specifying stratify=amazon_df['sentiment'], we ensure that both training and testing data containe around 93% positive sentiment.
#%% STEP2: Split the data into train and test sample
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(amazon_df['reviewText'],
amazon_df['sentiment'],
test_size=0.2,
random_state=42,
stratify=amazon_df['sentiment'])
print (f'Size of Training Data: {x_train.shape[0]} (reviews)')
print (f'Size of Test Data: {x_test.shape[0]} (reviews)')
print ('Distribution of classes in Training Data :')
print (f'Positive Sentiment {(sum(y_train == 1)/ len(y_train) * 100.0):.2f}%')
print (f'Negative Sentiment {(sum(y_train == 0)/ len(y_train) * 100.0):.2f}%')
print ('Distribution of classes in Testing Data :')
print (f'Positive Sentiment {(sum(y_test == 1)/ len(y_test) * 100.0):.2f}%')
print (f'Negative Sentiment {(sum(y_test == 0)/ len(y_test) * 100.0):.2f}%')
Size of Training Data: 1249 (reviews)
Size of Test Data: 313 (reviews)
Distribution of classes in Training Data :
Positive Sentiment 92.47%
Negative Sentiment 7.53%
Distribution of classes in Testing Data :
Positive Sentiment 92.65%
Negative Sentiment 7.35%
In Step 3, we construct the feature variables. More specifically, our feature variables consist of the words in the Document-Term Matrix produced by the sklearn.feature_extraction.text’s TfidfVectorizer. The basic idea is that some specific words may be more strongly associated with positive review rating (sentiment = 1 in the target variable). If that is the case, then the SVM algorithim will be able to pick up the pattern from the training data such that when we provide the set of TFIDF vectors in the test data we can get a reasonably good predictive performance.
The construction of the TfidfVectorizer is done by the following statement:
tfidf = TfidfVectorizer(min_df = 10, ngram_range=(1,1))
In the above statement, we set ngram_range=(1,1) because, for this example, we only want the “term” in the TFIDF vectors to consist only of unigram (i.e. single word). If we want to also consider bigram (i.e. two word phrases to capture compound terms), then we can set ngram_range=(1,2). In addition, we also set the parameter min_df=10 to drop any terms that appear too infrequently (min_df=10 means ignore terms that appear in less than 10 documents). The default value for min_df is 1, which means “ignore terms that appear in less than 1 document”.
#%% STEP3: Vectorizing the reviewText using TF-IDF vector representations
#(This step is needed because Machine Learning does not understand text)
#import the TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
#identify the vocabulary
#Note1: here setting ngram_range=(1,1) means we only consider unigram (i.e. single word)
#if we want to consider unigram and bigram (two word phrases) then ngram_range=(1,2)
#Note2: the parameter min_df is to remove terms that appear too infrequently.
#min_df=10 means ignore terms that appear in less than 10 documents.
#The default min_df is 1, which means "ignore terms that appear in less than 1 document".
tfidf = TfidfVectorizer(min_df = 10, ngram_range=(1,1))
#create the document term matrix for the train and test data
x_train_tf = tfidf.fit_transform(x_train)
x_test_tf = tfidf.transform(x_test)
#if you are curious to browse the document term matrix
x_train_tf_df = pd.DataFrame(x_train_tf.toarray(),
columns=tfidf.get_feature_names_out())
x_train_tf_df.tail()
| about | actually | ad | add | advice | after | again | all | already | also | ... | wonderful | work | world | worth | would | write | year | you | young | your | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1244 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.0 |
| 1245 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.0 |
| 1246 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.237294 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.109506 | 0.0 | 0.0 |
| 1247 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.0 |
| 1248 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.058187 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.167409 | 0.0 | 0.000000 | 0.0 | 0.0 |
5 rows × 346 columns
In Step 4, the actual training of the SVM Classfier is performed. In this example, we will use the LinearSVC (an SVM algorithm). You may try other algorithm
such as randomforest to see if there is improvement in predictive performance. Once the model is trained (by calling the .fit() method), we make prediction by calling the .predict() method, supplying the test data of the features: x_test_tf. The result of .predict() is a Numpy array, which we convert to DataFrame to quickly peek its first five values.
#%% STEP4: Train the Machine Learning model and produce prediction
from sklearn.svm import LinearSVC
model1 = LinearSVC(random_state=42, tol=1e-5)
model1.fit(x_train_tf, y_train)
y_pred = model1.predict(x_test_tf)
# peek at y_pred values
pd.DataFrame({'y_pred':y_pred}).head()
c:\Users\apalangkaraya\Anaconda3\lib\site-packages\sklearn\svm\_classes.py:32: FutureWarning: The default value of `dual` will change from `True` to `'auto'` in 1.5. Set the value of `dual` explicitly to suppress the warning.
warnings.warn(
| y_pred | |
|---|---|
| 0 | 1 |
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 1 |
In Step 5, which is the last step, we evaluate the predictive performance of our SVM Classifier by comparing the value of y_pred to y_test (the true observed value of the sentiment target variable as we defined in Step 0). We consider two predictive performance metrics: accuracy and ROC-AUC.
The results seem to suggest a reasonably good predictive performance with Accuracy Score = 0.96 and ROC-AUC Score = 0.76. Furthremore, when we compared the predictive performance of our SVM Classifier and the Bing Liu Lexicon, we find that the Bing Liu Lexicon Accuracy of 0.79 seems to be significantly lower than the 0.96 Accuracy Score of the SVM Classifier.
#%% STEP5: Evaluating the predictive performance
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
print (f'Accuracy Score: {accuracy_score(y_test, y_pred):.2f}')
print (f'ROC-AUC Score: {roc_auc_score(y_test, y_pred):.2f}')
#look at some sample
sample_reviews = amazon_df.sample(5)
sample_reviews_tf = tfidf.transform(sample_reviews['reviewText'])
sentiment_predictions = model1.predict(sample_reviews_tf)
sentiment_predictions = pd.DataFrame(data = sentiment_predictions,
index=sample_reviews.index,
columns=['sentiment_prediction'])
sample_reviews = pd.concat([sample_reviews, sentiment_predictions], axis=1)
print ('Some sample reviews with their sentiment - ')
print(sample_reviews[['text_orig','sentiment_prediction']])
#%% Comparing with the Bing Liu Lexicon sentiment classification
#Next, compare the accuracy of BingLiu Lexicon
def baseline_scorer(text):
score = bing_liu_score(text)
if score > 0:
return 1
else:
return 0
y_pred_baseline = x_test.apply(baseline_scorer)
acc_score = accuracy_score(y_pred_baseline, y_test)
print()
print('Predictive Performance Comparison\n')
print (f'Bing Liu Lexicon Accuracy: {acc_score:.2f}')
print (f'SVM Machine Learning Accuracy: {accuracy_score(y_test, y_pred):.2f}')
Accuracy Score: 0.96
ROC-AUC Score: 0.76
Some sample reviews with their sentiment -
text_orig sentiment_prediction
2204 good realistic receipes. Good variety too! Tri... 1
2154 Can't wait to read 1
1447 Quickly shipped. Loved this item 1
554 Consumer Reports has been around for years and... 1
937 High quality magazine. Lots of reviews about ... 1
Predictive Performance Comparison
Bing Liu Lexicon Accuracy: 0.79
SVM Machine Learning Accuracy: 0.96
Introduction to Topic Modelling#
A topic can be thought of as set of words that “go together”. For examples, when we think of “sports” as a topic, then the set of words that may come to mind consist of “athlete”, “stadium”, “game”, “soccer”, “Olympics”, etc. This is because these words usually go together as the words associated with “sports” as a topic. To consider another example, the words such as “Chanelle”, “boutique”, “dress”, “New York”, and “Chadstone” may go together under the topic of “fashion”.
What is topic modelling and how to do it?#
In essence, topic modelling is a statistical learning (i.e. machine learning) modelling to automatically discover the set of possible topics associated with a given corpus (i.e. a collection of documents). A corpus such as the whole Wikipedia are likely to contain many different topics which are mostly latent from the point of view the reader of the corpus. In topic modelling, a topic is defined as the probability distribution over a fixed set of words contained in the corpus. To take our topic definition earlier, we can think of a topic as containing “the set of words that come to mind when referring to this topic” and the probability mass associated to each of these words. For example, if we combined the previous two groups of words which go together under the sports and fashion topics, then we can expect that for the sports topic, the words such as “athlete” and “Olympics” would have higher probability mass than the words such as “dress” and “Chanelle”. Similarly, the topic of a document as a whole can be thought of as the probability distribution over a fixed set of latent topics associated to the words set within the document. This probability distritbution over latent topics reveals the topic of the document.
Doing topic modelling is basicall the same as estimating a machine learning model which represent each latent topic’s probability distribution over words in the document and the the probability over the latent topics’s in the document as a whole. One of the most often used topic models is known as the Latent Dirichlet Allocation (a.k.a the LDA) model. LDA is a probabilistic generative model and in Python there are several modules which offer LDA trainers including Gensim, scikit-learn, and many others. Other topic models beside LDA include, for examples, Latent Semantic Analysis (LSA), Probabilistic Latent Semantic Analysis (PLSA), and Correlated Topic Models (CTM).
A full discussion of the mathematics and statistics behind the algorithm for the LDA model is beyond our course, however in essence in can be summarised into the following steps:
Start with a fixed number of latent topics
For each topic k, sample a topic-word distribution ϕk ~ Dir(β)
For each document “d”, sample a document-topic distribution θd ~ Dir(α)
For each word w in document “d”, sample a topic zdw ~ Multinomial(θd) and sample a word wdw ~ Multinomial(ϕzdw)
The output of these steps would be:
A list of topics and for each topic, a probability distribution over words.
For each document, a probability distribution over the topics.
Doing LDA topic modelling on Australian Research Council project summary#
Every year, the Australian Research Council (ARC) awards research grants to successful grant applications from academic researchers based in Australian universities (who may have overseas collaboration partners). In their project proposal, these researchers provide a project summary description which explains in one or two paragraphs what their proposed projects are all about. Below are actual text of two such project summaries:
Grant Application 1: Optimum control of the in-use performance of talc-based compositions. It is important to improve the quality of their Talcom body powder, baby powder and other cosmetic products involving talc. The areas that can and need to be improved are shining characteristics, assessing the slip properties as well as developing the cosmetic chemistry of talc and other additives. The proposed project will generate: a) simple but reliable test methods for measuring slip and shine, b) methods for control of the physical and chemical characteristics of talc blends, c) mathematical model(s) for property and process control, which is useful to improvement of the final talc properties and in-use service.
Grant Application 2: Application of Silver Coatings to medical Devices for Antimicrobial Properties using Electroless Deposition. Silver compounds, eg. in topical creams, can be used to treat chronic infections. The results are mediocre, and there may be significant side effects. Metallic silver when coated on bandages or medical devices is gaining wider acceptance, but the dissolution rate must be improved to minimise infection. In this project an electroless silver coating process will be developed, with bath chemistry and coating conditions optimised for an ideal dissolution rate. This project will lead to the development of improved medical devices that will have significant social and economic benefits for Australia.
In the example below, we will develop a basic LDA model to extract 50 possible latent topics from a sample of 1,000 granted ARC project proposal. The text data are contained in a CSV file where each row represents a single project proposal (which we will call as a single document):
# ARC Project Grant Summary Data
arcdesc = pd.read_csv('ARCLP1.csv')
arcdesc.info()
# Pre-processed the grant summary text
arcdesc['grantsummary'] = arcdesc['grant-summary'].apply(preptext, args=(False,True))
The first step we do after loading the ARC project proposal text data is to pre-process the project summary text that we want to model. This text is under the column grant-summary. To do the text pre-processing, we .apply() a custom pre-processing function preptext() on each row (i.e., each document). The resulting pre-processed text is saved as a separate column grantsummary.
import pandas as pd
import re
#%% Pre-procesing function for Topic modelling ARC Grant Project Summary
commonwords = ['national', 'include', 'expect', 'understand', 'benefit', 'study',
'novel', 'approach', 'result', 'test', 'an', 'aim', 'by', 'this',
'with', 'australian', 'australia', 'that', 'have', 'their', 'on',
'such', 'can', 'these', 'how', 'from', 'use', 'also', 'well',
'project', 'may', 'whether', 'year', 'per', 'cent', 'proposal',
'u', 'provide', 'would', ]
my_stopwords = nltk.corpus.stopwords.words('english') + commonwords
word_rooter = nltk.stem.snowball.PorterStemmer(ignore_stopwords=False).stem
my_punctuation = '!"$%&\'()*+,-./:;<=>?[\\]^_`{|}~•@'
# preparing the text for topic modelling
def preptext(texttoclean, bigrams=False, lemmatize=False):
from nltk import word_tokenize, sent_tokenize
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def get_wordnet_pos(word):
""" Get Part-of-speech (POS) tag of input word, and return the first POS
tag character (which is the character that lemmatize() accepts as input)
"""
from nltk import pos_tag
from nltk.corpus import wordnet
tag_firstchar = pos_tag([word])[0][1][0].upper()
tag_dict = {'J': wordnet.ADJ,
'N': wordnet.NOUN,
'V': wordnet.VERB,
'R': wordnet.ADV}
return tag_dict.get(tag_firstchar, wordnet.NOUN) # Note that the default value to return is "N" (NOUN)
texttoclean = texttoclean.lower() # lower case
texttoclean = re.sub('['+my_punctuation + ']+', ' ', texttoclean) # strip punctuation
texttoclean = re.sub('\s+', ' ', texttoclean) #remove double spacing
texttoclean = re.sub('([0-9]+)', '', texttoclean) # remove numbers
texttoclean_token_list = [word for word in texttoclean.split(' ')
if word not in my_stopwords] # remove stopwords
# texttoclean_token_list = [word_rooter(word) if '#' not in word else word
# for word in texttoclean] # apply word rooter
# print(texttoclean_token_list)
if lemmatize:
# texttoclean = [lemmatizer.lemmatize(word, pos=get_wordnet_pos(word)) for word in texttoclean]
texttoclean = [lemmatizer.lemmatize(word) for word in texttoclean]
if bigrams:
texttoclean_token_list = texttoclean_token_list+[texttoclean_token_list[i]+'_'+
texttoclean_token_list[i+1]
for i in range(len(texttoclean_token_list)-1)]
texttoclean = ' '.join(texttoclean_token_list)
return texttoclean
#%% Topic Modelling of ARC Grant Project Summary
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
# ARC Project Grant Summary Data
arcdesc = pd.read_csv('ARCLP1.csv')
arcdesc.info()
# Pre-processed the grant summary text
arcdesc['grantsummary'] = arcdesc['grant-summary'].apply(preptext, args=(False,True))
arcdesc[['grantsummary', 'grant-summary']].head()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 code 1000 non-null object
1 scheme-name 1000 non-null object
2 funding-commencement-year 1000 non-null int64
3 scheme-information 1000 non-null object
4 current-admin-organisation 1000 non-null object
5 announcement-admin-organisation 1000 non-null object
6 grant-summary 1000 non-null object
7 lead-investigator 1000 non-null object
8 current-funding-amount 1000 non-null int64
9 announced-funding-amount 1000 non-null int64
10 grant-status 1000 non-null object
11 primary-field-of-research 1000 non-null object
12 anticipated-end-date 1000 non-null object
13 investigators 1000 non-null object
14 lief-register 0 non-null float64
15 national-interest-test-statement 0 non-null float64
dtypes: float64(2), int64(3), object(11)
memory usage: 125.1+ KB
| grantsummary | grant-summary | |
|---|---|---|
| 0 | optimum control performance talc based composi... | Optimum control of the in-use performance of t... |
| 1 | application silver coatings medical devices an... | Application of Silver Coatings to medical Devi... |
| 2 | qua queensland digital ultra atlas aims design... | QUA:Queensland digital Ultra-Atlas. This proje... |
| 3 | electronic properties diamondlike carbon appli... | Electronic properties of diamondlike carbon fo... |
| 4 | intermittent reinforcement scheduling improvin... | Intermittent reinforcement scheduling: Improvi... |
Getting the topics and the probability distribution over the terms#
Once we have a pre-processed text, we invoke sklearn’s CountVectorizer where we specify to ignore terms which appear in more than 50% of the documents (max_df = 0.50), term which appears too infrequently in less than 1% of the documents, and to consider only single words and no digits ('\w+|\$[\d\.]+|\S+'). As an example, these parameters are set for illustration purpose only. In practice, you would need to try to set the parameters by analysing their effects on the quality of the topics produced.
# the vectorizer object will be used to transform text to vector form
vectorizer = CountVectorizer(max_df=0.50, min_df=0.01, token_pattern='\w+|\$[\d\.]+|\S+')
# apply transformation to get document-term-matrix based on Count Vector
tf = vectorizer.fit_transform(arcdesc['grantsummary']).toarray()
Later on, for topic labelling purpose, we will need the actual terms produced by CountVectorizer which could be associated with each topic. These terms can be obtained by the following statement:
# tf_feature_names tells us what word each column in the matric represents
# tf_feature_names = vectorizer.get_feature_names()
tf_feature_names = vectorizer.get_feature_names_out()
Then, to estimate the LDA model, need to specify the number of latent topics to identify. For replication, we also set the random generator seed.
# LDA model
number_of_topics = 50
model = LatentDirichletAllocation(n_components=number_of_topics, random_state=0)
model.fit(tf)
# a simple function to display the topics
def display_topics(model, feature_names, no_top_words):
topic_dict = {}
for topic_idx, topic in enumerate(model.components_):
topic_dict["Topic %d words" % (topic_idx)]= ['{}'.format(feature_names[i])
for i in topic.argsort()[:-no_top_words - 1:-1]]
topic_dict["Topic %d weights" % (topic_idx)]= ['{:.1f}'.format(topic[i])
for i in topic.argsort()[:-no_top_words - 1:-1]]
return pd.DataFrame(topic_dict)
# Number of top words to display
no_top_words = 10
# Display the top words for each topic
topics50df = display_topics(model, tf_feature_names, no_top_words)
Lastly, the results of LatentDirichletAllocation() is a Sparse Matrix object. To facilitate for viewing the list of topics produced, we write a custom function (display_topics()) which require three inputs:
model: the estimated/fitted LDA model
feature_names: the names of the terms
no_top_words: the number of the top terms we want to consider to represent the topics
In this example, we will consider the top 10 terms (i.e. ten terms with the highest probability mass for each topics). The image below shows a truncated snapshot of the DataFrame topics50df. So, for example, the first topic is associated the terms [‘surface’, ‘resource’, ‘south’, ‘steel’, ‘remote’ ….] as the first five of the top 10 terms. We can think of these top 10 firms are the terms which define Topic 0. As we specified, the DataFrame topics50df contain the top 10 terms (and their respective probability masses) for each of the 50 topics.
# the vectorizer object will be used to transform text to vector form
vectorizer = CountVectorizer(max_df=0.50, min_df=0.01, token_pattern='\w+|\$[\d\.]+|\S+')
# apply transformation to get document-term-matrix based on Count Vector
tf = vectorizer.fit_transform(arcdesc['grantsummary']).toarray()
# tf_feature_names tells us what word each column in the matric represents
# tf_feature_names = vectorizer.get_feature_names()
tf_feature_names = vectorizer.get_feature_names_out()
# LDA model
number_of_topics = 50
model = LatentDirichletAllocation(n_components=number_of_topics, random_state=0)
model.fit(tf)
# a simple function to display the topics
def display_topics(model, feature_names, no_top_words):
topic_dict = {}
for topic_idx, topic in enumerate(model.components_):
topic_dict["Topic %d words" % (topic_idx)]= ['{}'.format(feature_names[i])
for i in topic.argsort()[:-no_top_words - 1:-1]]
topic_dict["Topic %d weights" % (topic_idx)]= ['{:.1f}'.format(topic[i])
for i in topic.argsort()[:-no_top_words - 1:-1]]
return pd.DataFrame(topic_dict)
# Number of top words to display
no_top_words = 10
# Display the top words for each topic
topics50df = display_topics(model, tf_feature_names, no_top_words)
topics50df.head()
| Topic 0 words | Topic 0 weights | Topic 1 words | Topic 1 weights | Topic 2 words | Topic 2 weights | Topic 3 words | Topic 3 weights | Topic 4 words | Topic 4 weights | ... | Topic 45 words | Topic 45 weights | Topic 46 words | Topic 46 weights | Topic 47 words | Topic 47 weights | Topic 48 words | Topic 48 weights | Topic 49 words | Topic 49 weights | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | surface | 36.3 | knowledge | 19.6 | health | 27.1 | systems | 14.7 | public | 21.1 | ... | development | 22.7 | research | 9.7 | cultural | 47.0 | processing | 36.8 | development | 21.3 |
| 1 | research | 14.7 | design | 15.5 | research | 22.3 | plant | 14.5 | history | 21.0 | ... | materials | 19.1 | water | 9.0 | research | 41.5 | development | 19.2 | data | 15.7 |
| 2 | south | 14.0 | protein | 11.9 | public | 20.2 | based | 10.7 | western | 14.1 | ... | new | 15.5 | control | 9.0 | management | 33.1 | devices | 14.5 | research | 15.6 |
| 3 | steel | 12.1 | gold | 11.8 | management | 17.2 | disease | 10.2 | research | 10.4 | ... | quality | 12.2 | behaviour | 8.1 | industry | 29.3 | based | 13.7 | develop | 15.4 |
| 4 | remote | 10.1 | technology | 11.3 | community | 14.4 | marine | 9.7 | outcomes | 10.3 | ... | genes | 11.7 | food | 7.5 | heritage | 19.0 | develop | 12.7 | systems | 15.1 |
5 rows × 100 columns
Labelling the topics and probability distribution over the topics#
Ideally, we would want to have an “English” label for each of the topics instead of calling them as Topic 0, Topic 1, …, etc. In this example, we will attempt to manually label each topic based on the top 10 terms. For more advanced topic modelling, there are some alternatives which have been proposed to do automatic labelling of LDA topics. For examples, see the discussion here and other related articles.
Once we have a label for each of the topic, we can compute the probabilitu distribution over topic for each document in order to chracterise the topic of each document. Recall that in this example, a document is a funded ARC grant project proposal. Thus, effectively, we can now say what each project proposal’s topic is and group the project proposals based on their common topic and do further analyses. For simplicity, we will only consider the top 3 topics associated with each document as shown in the DataFrame doctoptopic.
doc_topic_dist = model.transform(tf)
# Each document's probabilistic distribution over the topics
doctopicdistdf = pd.DataFrame(doc_topic_dist, columns=topics50)
#top topic for each doc
df = doctopicdistdf
doctoptopic = df.apply(lambda x: pd.Series(x.sort_values(ascending=False)
.iloc[:3].index,
index=['top50_1','top50_2','top50_3']), axis=1).reset_index()
For example, if we only consider the top 1 topic label, then Project Proposal #1 is about “regional-data-support; Project Proposal #2 is about “road-drivers-researc”; and Project Proposal #3 is about “cultural-history”.
# topic labels (manual labelling based on keywords of each topic in topics50df)
topics50 = ['1.metal-surface', '2.knowledge-design-protein-gold','3.public-health-management',
'4.plant-based-systems-disease', '5.western-history', '6.road-drivers-research',
'7.drug-controlled-release', '8.industry-data-control', '9.effective-industry-system',
'10.water-flow-model', '11.industry-labor-model', '12.industrial-gas-housing',
'13.rural-effects-model', '14.oil-industry-performance', '15.high-species-control',
'16.blood-cell-system', '17.water-management', '18.mobile-based-applications',
'19.young-children-policy', '20.indigenous-disease-drug', '21.school-learning',
'22.new-blood-services', '23.fish-environmental', '24.native-plant-design',
'25.age-care-services', '26.regional-data-support', '27.water-nutrient-forest',
'28.new-systems-seed','29.new-fish-control', '30.mobile-data-pressure',
'31.arts-data-research', '32.water-transfer-system', '33.networks-growth-policy',
'34.social-rural-community', '35.industry-based-water', '36.social-change',
'37.information-support-services', '38.new-species-development', '39.cell-support-system',
'40.research-test-data', '41.human-safety-policy', '42.cultural-history',
'43.molecular-management', '44.water-system',
'45.urban-ecological-risk', '46.genes-disease-quality', '47.water-control-behavior',
'48.cultural-management', '49.devices-processing', '50.genetic-data-development']
doc_topic_dist = model.transform(tf)
# Each document's probabilistic distribution over the topics
doctopicdistdf = pd.DataFrame(doc_topic_dist, columns=topics50)
#top topic for each doc
df = doctopicdistdf
doctoptopic = df.apply(lambda x: pd.Series(x.sort_values(ascending=False)
.iloc[:3].index,
index=['top50_1','top50_2','top50_3']), axis=1).reset_index()
doctoptopic.head()
| index | top50_1 | top50_2 | top50_3 | |
|---|---|---|---|---|
| 0 | 0 | 26.regional-data-support | 39.cell-support-system | 49.devices-processing |
| 1 | 1 | 6.road-drivers-research | 49.devices-processing | 1.metal-surface |
| 2 | 2 | 42.cultural-history | 2.knowledge-design-protein-gold | 5.western-history |
| 3 | 3 | 11.industry-labor-model | 1.metal-surface | 39.cell-support-system |
| 4 | 4 | 6.road-drivers-research | 34.social-rural-community | 21.school-learning |